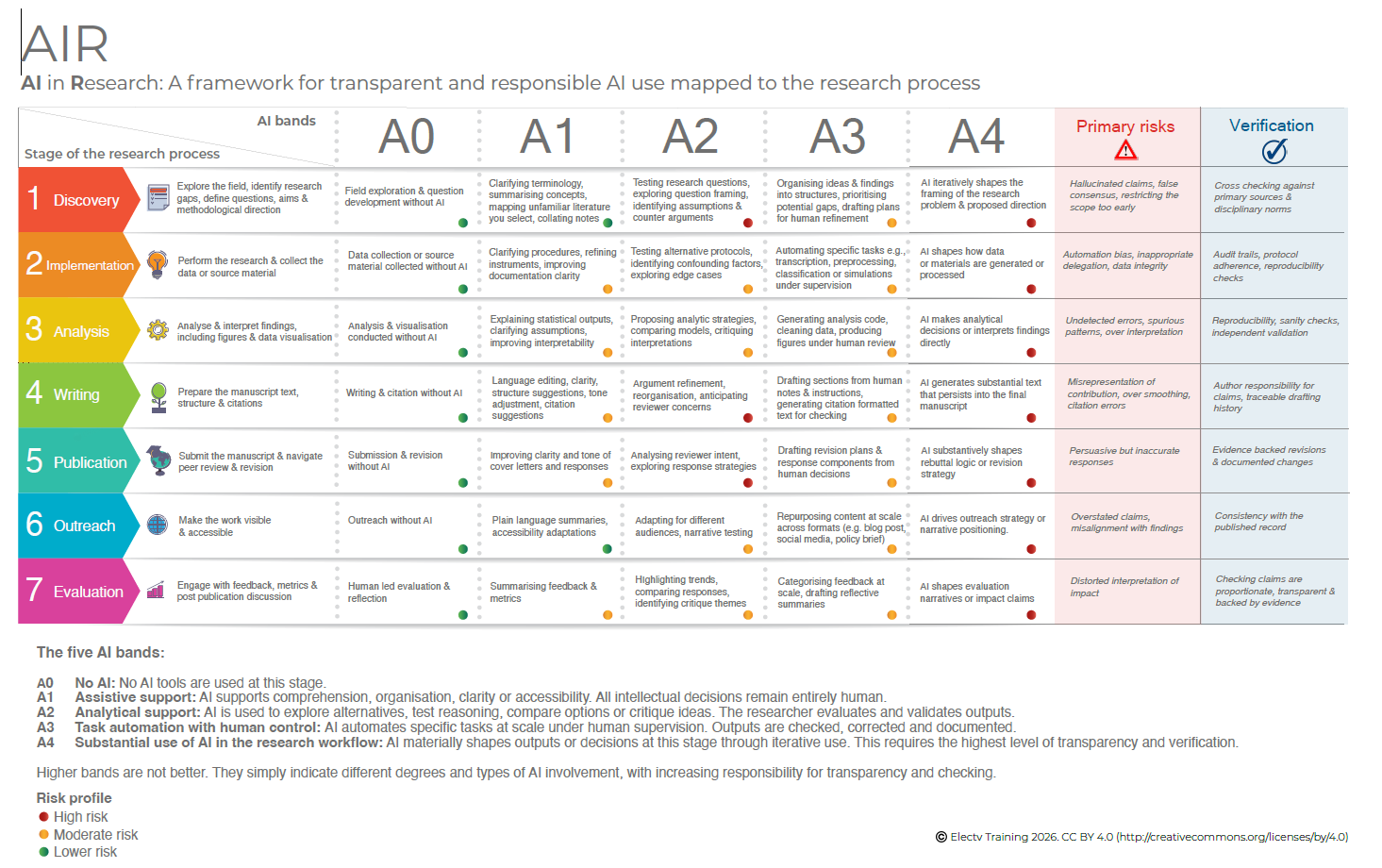
Marco AIR para uso responsable de IA: útil pero revelador de nuestras inconsistencias
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
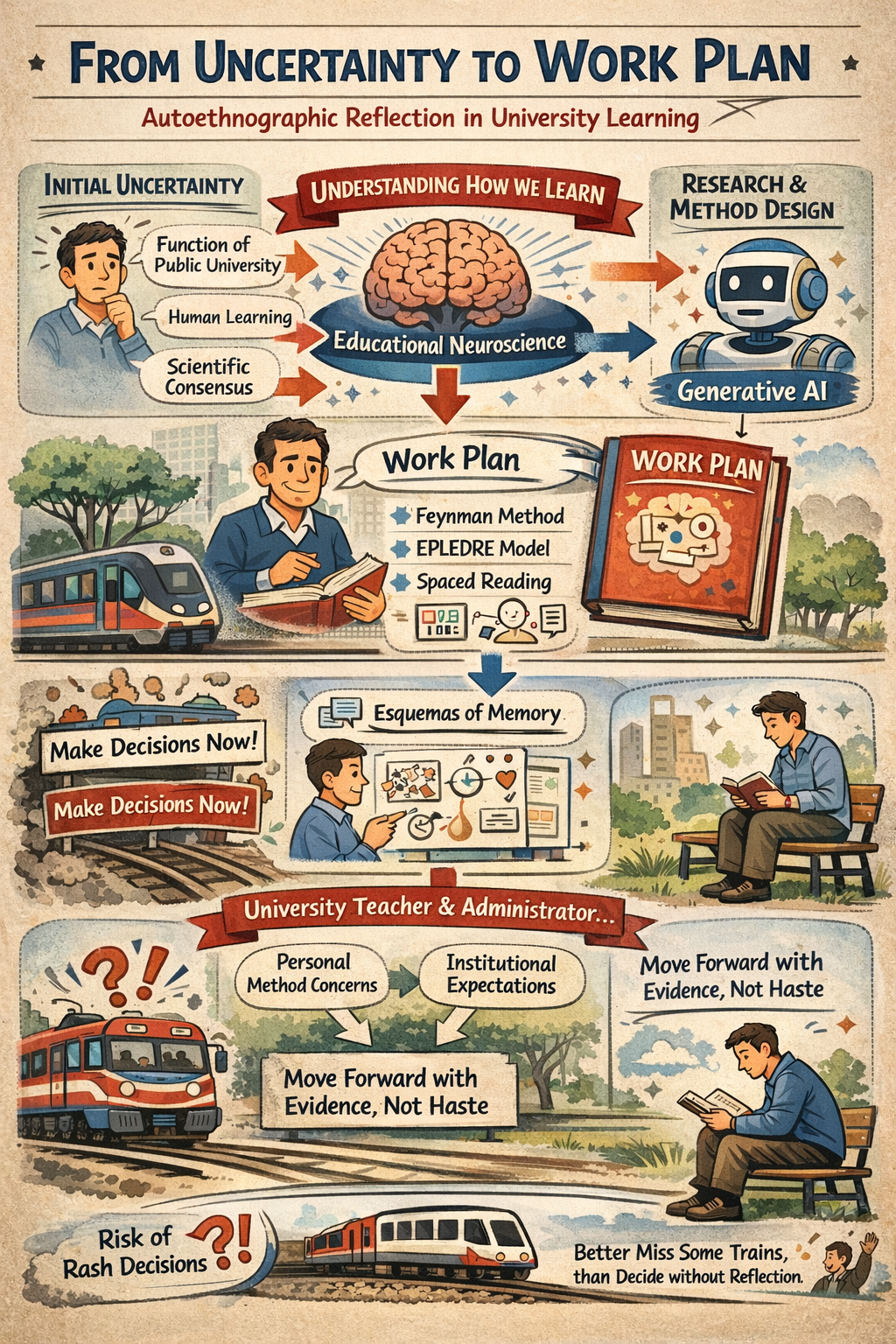
Creo que es muy útil para resolver algunas de las dudas que surgen en mis charlas sobre IA generativa en Research.
Con esta tabla, en menos de 5 minutos, puedes informar con transparencia sobre el uso que has hecho de la IA y las verificaciones que has realizado (la última columna) para estar seguro de que lo etiquetado como riesgo moderado no representa ningún “concern” para la validez de tu trabajo.
Intentar justificar que lo etiquetado como riesgo elevado no te afecta podría dar lugar a un artículo por cada una de las casillas de la columna A4.
Y este es el talón de Aquiles de todo esto… si alguien te obliga a demostrar punto por punto que estás exento de riesgos y sesgos, igual necesitas uno o dos años de trabajo para justificar adecuadamente cualquier artículo… incluso los que has escrito completamente “a mano” sin ayuda de ninguna IA generativa.
Es un poco sorprendente el doble rasero que se aplica, no pidiendo ninguna justificación si lo haces tú solito (proyectando todas tus torpezas y sesgos implícitos), y abrumándote con justificaciones si te apoyas en IA generativa. No, si no está prohibido que la uses, pero si dices que la usas, debes invertir una burrada de horas de trabajo para justificar “adecuadamente” que el uso ha sido correcto.
¿Alguien me ha preguntado alguna vez si he usado correctamente SPSS en los artículos que he escrito en los últimos 30 años? ¡Pero si, las veces que intento adjuntar la sintaxis, los revisores me dicen que quite esa información porque les “despista” y hace innecesariamente largo el artículo!
Visitas: 82