1) Trabajando en equipo en entornos presenciales, remotos e híbridos: Enlace a inscripción (disponible desde diciembre 2022-) 2) Liderazgo de equipos remotos: Enlace a inscripción (disponible desde noviembre 2022 -inicio curso marzo 2023-) 3) Habilidades de Comunicación interpersonal adaptada a equipos remotos: Enlace a inscripción (disponible desde noviembre 2022 -inicio curso mayo 2023-)
(versiones en inglés a partir de noviembre 2023)
Las competencias transversales (soft skills) son esenciales en prácticamente todos los puestos de trabajo actuales y complementan a las competencias técnicas (hard skills) para construir un perfil exitoso de las personas que abanderan/representan el talento de una organización. Para este programa hemos seleccionado un conjunto de tres competencias transversales cruciales (Trabajar en equipo, Influir positivamente en el comportamiento de las personas del equipo y comunicarse de manera efectiva con ellas). Este programa proporciona habilidades para trabajar en equipo en un entorno remoto, algo que ya es habitual en todas las instituciones y empresas y que cada vez lo será más.
Se sabe mucho sobre cómo usar estas competencias en entornos presenciales (y edX tiene ya moocs de esto). Sin embargo , existe un hueco en formación sobre cómo adaptar los comportamientos esenciales en cada competencia cuando el equipo trabaja remotamente.
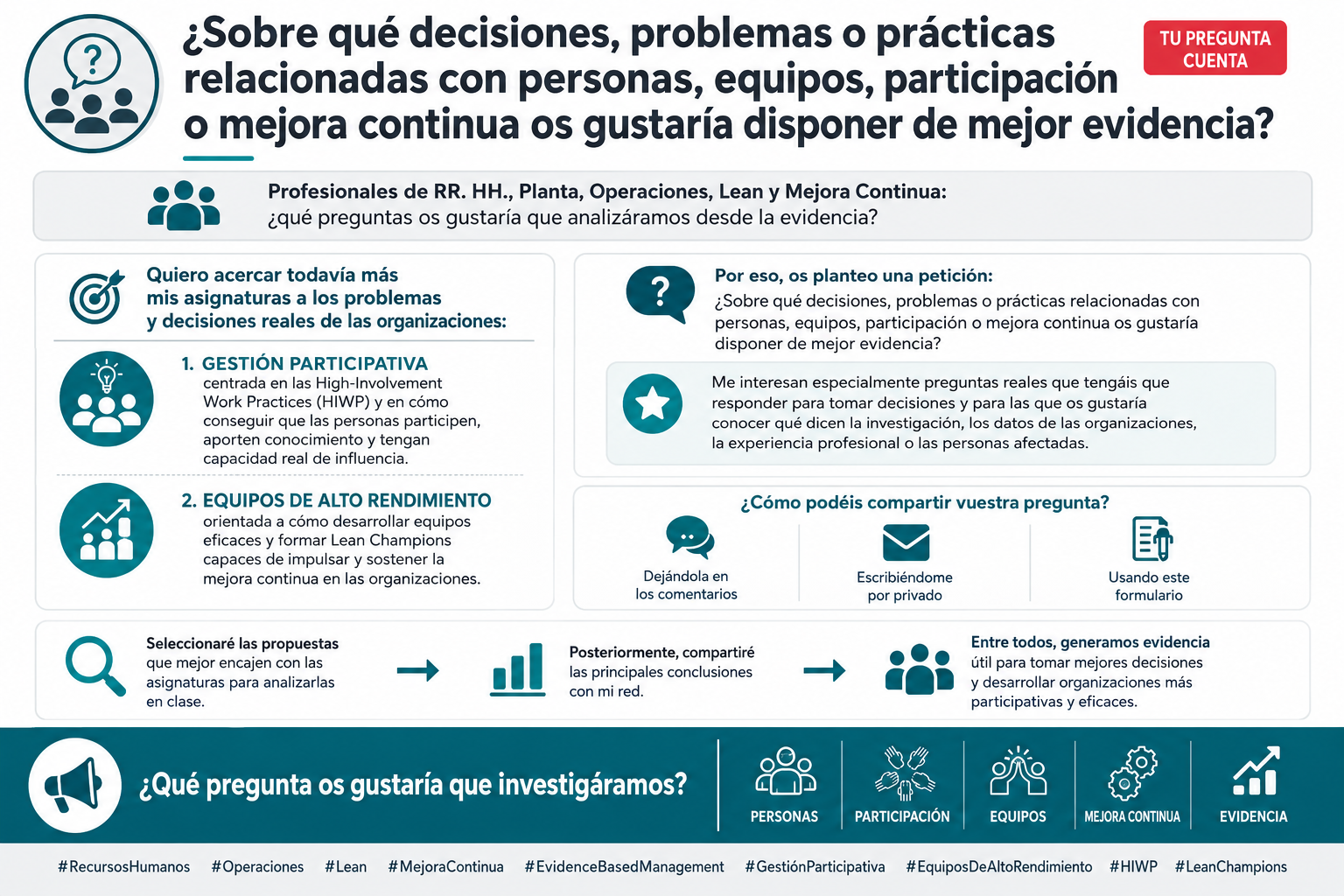
Profesionales de RR. HH., Planta, Operaciones, Lean y Mejora Continua: ¿qué preguntas os gustaría que analizáramos desde la evidencia?
Quiero acercar todavía más mis asignaturas a los problemas y decisiones reales de las organizaciones:
🔹 Gestión Participativa, centrada en las High-Involvement Work Practices (HIWP)y en cómo conseguir que las personas participen, aporten conocimiento y tengan capacidad real de influencia.
🔹 Equipos de Alto Rendimiento, orientada a cómo desarrollar equipos eficaces y formar Lean Champions capaces de impulsar y sostener la mejora continua en las organizaciones
Por eso, os planteo una petición:
¿Sobre qué decisiones, problemas o prácticas relacionadas con personas, equipos, participación o mejora continua os gustaría disponer de mejor evidencia?
Me interesan especialmente preguntas reales que tengáis que responder para tomar decisiones y para las que os gustaría conocer qué dicen la investigación, los datos de las organizaciones, la experiencia profesional o las personas afectadas.
Seleccionaré las propuestas que mejor encajen con las asignaturas para analizarlas en clase y, posteriormente, compartiré las principales conclusiones con mi red.
I use a digital reading platform because the book I need is not available in print. I want to read it. Nothing more, and nothing less.
And yet Bookshelf+ puts an artificial intelligence assistant front and center, offering to simplify concepts, create quizzes and summaries, and answer questions about the book. It is not a discreet tool that I can activate when I need it. It is the first layer of the reading experience. And I definitely do not want that.
I do not mind that other people may find this feature useful. What I object to is having it visually imposed on me, occupying a privileged space and shaping my relationship with the text from the very beginning. If I decide to use AI, I will do so when I believe it can help me.
When I buy a physical book and open it to the first page, a genie does not pop out of a lamp and ask whether I would like a summary. Thankfully. First, I read, think, connect ideas, go back, underline, take notes, and try to understand the text for myself. Only when I get stuck do I look for help. That order matters.
Reading is not merely about extracting information as quickly as possible. It also means pausing, doubting, interpreting, making mistakes, and developing an interpretation of your own. A summary can be useful in certain circumstances, but it should not become the gateway to a book (least of all on a platform whose very purpose is supposed to be facilitating reading).
It is even more baffling that Bookshelf+ has devoted resources to integrating this assistant while still failing to provide even minimally competent annotation and highlighting tools. I cannot find a satisfactory way to work with my notes, export them, or integrate them with Zotero or Obsidian. Those are the kinds of features that would genuinely add value for someone reading for study, research, or work.
A good digital reading tool should help me make the text my own: highlight passages, write comments, organize ideas, preserve references, and transfer that work into my knowledge vault. Instead, the platform’s major investment appears to be an AI that offers to process the book on my behalf.
Bookshelf+ is embarking on a costly and uncertain venture that may ultimately make the book itself less necessary, while neglecting the features that would help people read it better. I need a platform that respects my attention and gives me effective tools for working with the text.
First, I want to read. Then, perhaps, I will ask for help.
El problema del performance management no es evaluar (Pulakos, Mueller Hanson, Arad y Moye, 2015). El sistema no está roto porque midamos, sino porque medimos algo que se ha desconectado de aquello a lo que debía servir. La evaluación se ha vuelto trámite (rellenar una casilla, cerrar el expediente) y ha dejado de asociarse a la conducta real que se pretende mejorar. Los que critican la evaluación del rendimiento no son cuatro recién llegados.
Deming (1986) ya metía la calificación anual por méritos entre sus enfermedades mortales, con el argumento de que atribuimos a la persona lo que en realidad produce el sistema. Da igual que hablemos de notas o de incentivos: el premio contingente parece fomentar la motivación extrínseca y erosiona la motivación intrínseca que es justo la que normalmente interesa potenciar. La métrica que sustituye el juicio profesional por un indicador, en cuanto tiene consecuencias, alguien aprende a maquillarla (Campbell, 1979; Strathern, 1997). Murphy (2020) ya escribió hace unos años: “performance evaluation will not die, but it should”.
Todo esto es anterior a la IA. Lo interesante es releerlo ahora porque la IA no ha traído un problema nuevo; ha añadido una capa encima de los de siempre. A los problemas de toda la vida (el sesgo del que evalúa, el trámite, el indicador que se maquilla) se suma ahora el postureo: que lo que evalúo no lo haya escrito quien lo firma, y que la propia evaluación tampoco la escriba quien la firma. El indicador se externaliza a una máquina. Y el filtro que teníamos, afinado durante décadas, no está preparado para esto.
Nuestra evaluación sumativa en la universidad está rota por lo mismo que el performance management. No porque la evaluación sumativa no sirva (sirve, y no voy a discutirlo), sino porque también se ha desconectado. La nota certifica cada vez menos lo que dice certificar, y la IA solo ha hecho visible una desconexión que ya venía de antes.
La tentación fácil es contestar “pues no evaluamos”, “quitamos el filtro” o “esto es demasiado difícil de evaluar, así que no lo evaluamos”. El reto es construir un marco para hacerlo bien, asumiendo que es complejo y que habrá que rehacerlo cuando cambien las condiciones. La dificultad de evaluar nunca ha sido excusa para dejar de evaluar, ha sido el motivo para diseñar mejor.
Es la misma conclusión de Murphy y DeNisi (2023): deshacerse de la evaluación no es la respuesta. Lo que toca es rediseñar, seguramente desde cero, no solo hacer normativas o recomendaciones (Corbin, Dawson, Nicola-Richmond y Partridge, 2025). Significa replantear la evaluación a nivel de programa y de forma colaborativa, algo que Nicola-Richmond, Dawson, Partridge y Macfarlane (2025) describen como un asunto de comunidad, más que de asignatura suelta. O sea, un trabajo enorme. No sabemos todavía cómo hacerlo bien en tiempo de IA, con el agravante de que ahora ni siquiera nos queda el consuelo del filtro viejo que, aunque fuera imperfecto, nos dejaba dormir tranquilos.
Referencias:
Campbell, D. T. (1979). Assessing the impact of planned social change. Evaluation and Program Planning, 2(1), 67–90. https://doi.org/10.1016/0149-7189(79)90048-X
Corbin, T., Dawson, P., & Liu, D. (2025). Talk is cheap: Why structural assessment changes are needed for a time of GenAI. Assessment & Evaluation in Higher Education, 50(7), 1087–1097. https://doi.org/10.1080/02602938.2025.2503964
Craig, P., Dieppe, P., Macintyre, S., Michie, S., Nazareth, I., & Petticrew, M. (2008). Developing and evaluating complex interventions: The new Medical Research Council guidance. BMJ, 337, a1655. https://doi.org/10.1136/bmj.a1655
Deming, W. E. (2000). Out of the Crisis. MIT Press.
Murphy, K., & DeNisi, A. (2023). New approaches to dealing with performance management: Getting rid of performance appraisals is not the answer. IIM Ranchi Journal of Management Studies, 2(2), 143–158. https://doi.org/10.1108/IRJMS-09-2023-0074
Murphy, K. R. (2020). Performance evaluation will not die, but it should. Human Resource Management Journal, 30(1), 13–31. (WOS:000490177200001). https://doi.org/10.1111/1748-8583.12259
Nicola-Richmond, K., Dawson, P., Helen, P., & Macfarlane, S. (2025). It takes a village… Program-wide approaches to redesigning assessment in a time of generative artificial intelligence (GenAI). Journal of University Teaching and Learning Practice, 22(7), e1711–e1711. https://doi.org/10.53761/zpp2ja61
Pulakos, E. D., Hanson, R. M., Arad, S., & Moye, N. (2015). Performance Management Can Be Fixed: An On-the-Job Experiential Learning Approach for Complex Behavior Change. Industrial and Organizational Psychology, 8(1), 51–76. https://doi.org/10.1017/iop.2014.2
Skivington, K., Matthews, L., Simpson, S. A., Craig, P., Baird, J., Blazeby, J. M., Boyd, K. A., Craig, N., French, D. P., McIntosh, E., Petticrew, M., Rycroft-Malone, J., White, M., & Moore, L. (2021). A new framework for developing and evaluating complex interventions: Update of Medical Research Council guidance. BMJ, 374, n2061. https://doi.org/10.1136/bmj.n2061
Strathern, M. (1997). ‘Improving ratings’: Audit in the British University system. European Review, 5(3), 305–321. https://doi.org/10.1002/(SICI)1234-981X(199707)5:3%253C305::AID-EURO184%253E3.0.CO;2-4
Si ChatGPT, Gemini o quien sea entra en el mercado de la educación, lo que nos está diciendo es que APRENDER tiene valor. Millones de personas dispuestas a pagar por aprender. Esa validación de mercado nos la acaban de regalar.
Si el futuro de la universidad depende de qué producto saquen las tecnológicas o de a qué precio lo pongan, entonces no tenemos servicio. Tenemos un trámite con sello oficial.
Y cuidado con consolarse con que “ellos son generalistas y no conocen a mis alumnos”. No es verdad. Los perfilan, los siguen conversación a conversación, los acabarán conociendo mejor que nosotros.
Si tu clase consiste en transmitir contenido y tramitar una calificación, ya tienes sustituto. Más barato, más paciente y disponible a las tres de la madrugada.
Lo que pasa es que los chatbots están entrenados para una sola cosa: que vuelvas mañana. Si para eso tienen que darte la razón, te la dan. Si tienen que ponértelo más fácil, te lo ponen. Si validarte te retiene, te validan. Es su modelo de negocio: tú no eres su estudiante, eres su retención.
A mí, que vuelvas mañana, me da igual. Lo que no me da igual es que, dentro de cinco años, sepas hacer tu trabajo. Por eso a veces te lo pongo difícil, te digo que no, o te digo cosas que no te gusta oír pero necesitas oír. Y cuando firmo que estás preparado, esa firma lleva mi nombre: si tú fallas ahí fuera, el que queda mal soy yo.
El error no es competir con la IA. El error es parecerse a ella.
Disclaimer: a mí siempre me ha gustado más trabajar con scripts que con menús y ventanas. Desde que hace unos 35 años empecé a usar SPSS, pasando por R y cualquier otro programa que me permita guardar un log de lo que he hecho como algo ejecutable en el futuro, me tienen robado el corazón. Así que esto que describo no es para todos los públicos.
Dicho esto: llevo años editando vídeos con Camtasia, MS Stream y otras aplicaciones. Funcionan bien. El problema no es solo que no puedas hacer batch. Es que algunas operaciones que parecen simples, en una herramienta con interfaz gráfica, se vuelven absurdamente lentas. Sacar diez fragmentos recortados de un vídeo en Camtasia puede costarte fácilmente dos horas: abrir el proyecto, marcar el inicio y el fin de cada fragmento, exportar, esperar el render y repetir si no ha salido como querías a la primera. Lo mismo con Adobe Premiere, Clipchamp, MS Stream, o cualquier otra herramienta con ventanas y botones. Están diseñadas para la edición creativa, para decidir qué hacer con un vídeo. No para procesar en volumen. No es un defecto, es que no es su caso de uso.
Si además tenemos en cuenta el tiempo de renderizado… Las herramientas con interfaz gráfica tienen que gestionar previsualización, efectos, capas… Aunque tú solo quieras cortar un fragmento. ffmpeg en local no tiene nada de eso; va directo al fichero y, en muchos casos, a una velocidad de vértigo.
El otro problema es la reproducibilidad. Si has tardado dos horas en sacar esos diez fragmentos y luego necesitas cambiar algo (el formato de salida, el punto de corte, lo que sea), vuelves a empezar casi desde cero. Con un script, cualquier modificación tarda solo segundos: cambias un parámetro, vuelves a ejecutar, y obtienes el resultado actualizado sobre todos los ficheros. Además, tienes por escrito exactamente qué has hecho, lo que no es fácil de recordar cuando ha pasado tiempo (aunque sea poco) desde que lo hiciste.
Este fin de semana he integrado ffmpeg a mi espacio de trabajo (es un año con intensas novedades: migrar de Ennote a Zotero, empezar con Obsidian, pasar de Jira a Clockify…). ffmpeg es una herramienta de línea de comandos (gratuita, de código abierto) que procesa vídeo y audio en local y acepta scripts. Puedes dividir un vídeo en fragmentos por tiempo, comprimir, cambiar de formato, extraer audio, recortar o concatenar, y hacerlo en modo batch sobre los ficheros de una carpeta entera sin tocar nada manualmente.
Localiza el ejecutable que necesitas es ffmpeg.exe, que está dentro de la subcarpeta bin. No hace falta instalarlo ni tocar el PATH si el ffmpeg.exe está en la misma carpeta donde tienes los scripts y lo llamas como .\ffmpeg.exe.
Si prefieres añadir la carpeta donde este el .ex al PATH para poder ejecutarlo desde cualquier carpeta tambien es una opcion (yo no la uso).
Los scripts: PowerShell + .bat
Yo escribo los scripts en PowerShell (.ps1) porque es más legible para lógica con bucles y condiciones. El único problema es que hacer doble clic en un .ps1 no lo ejecuta directamente en Windows debido a la política de ejecución por defecto. La solución es crear un fichero .bat que lo llame:
@echo off
powershell.exe -ExecutionPolicy Bypass -File "%~dp0tu_script.ps1"
pause
Con ese .bat en la misma carpeta que el .ps1, los videos y el ffmepg.exe haces doble clic y se ejecuta. El %~dp0 es la ruta de la carpeta donde está el .bat (así no depende de desde dónde lo lances), y el pause al final mantiene la ventana abierta para que puedas ver si ha habido algún error.
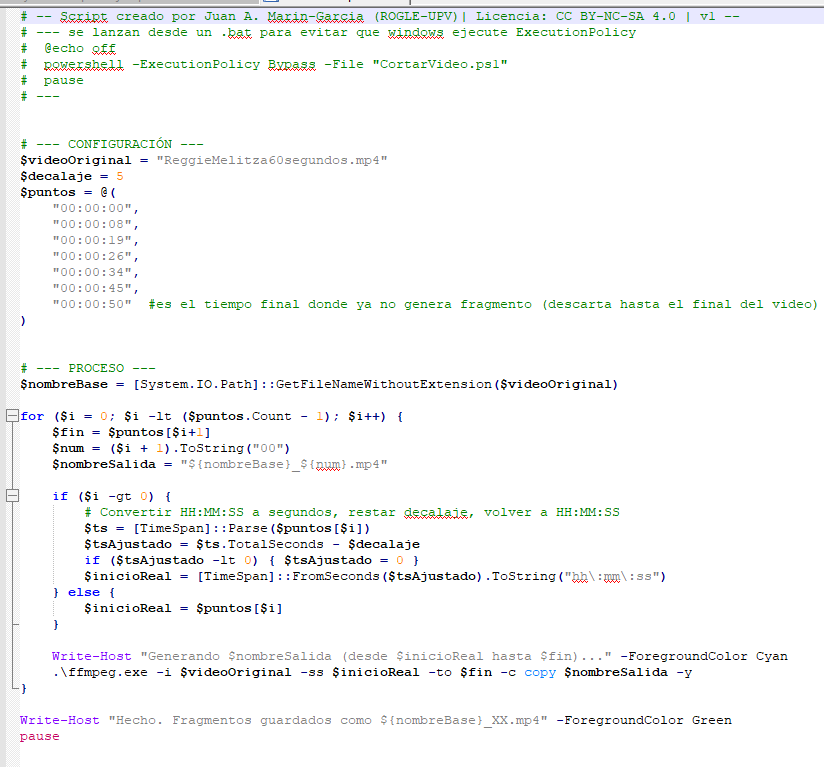
Un script básico que procesa todos los .mp4 de la carpeta actual tiene esta estructura:
Ajustas [tus opciones aquí] a lo que necesites y el script recorre todos los vídeos de la carpeta sin que tengas que hacer nada más.
El balance
Me costó unas dos horas montarme los scripts (era novato en ffmpeg y parte del tiempo fue entender qué opciones hacen qué). Ya me han ahorrado aproximadamente seis horas de trabajo este fin de semana en tareas que hago con regularidad. El retorno empieza a ser positivo, y va a seguir siéndolo cada vez que los reutilice.
Camtasia y similares no va a desaparecer de mi flujo para ediciones más elaboradas. Pero para procesar en batch, para tareas que se repiten, o simplemente para no perder una tarde haciendo a mano algo que dura treinta segundos en un script, merece la pena la inversión inicial.
Cuando la tecnología avanza en meses y la institución en años
Llevo como 3 años teniendo la intuición de que el modo en que “la gente” aborda el asunto de la IA gen en la universidad no me convence (los tipos de controles que plantean, los enfoques subyacentes, que son prácticamente reactivos, etc.). No sabía hacer explícito por qué me chirriaba tanto, simplemente tenía el síndrome del niño de “El traje nuevo del emperador” del cuento de H.C. Andersen. Hasta hoy. Gracias a este post de Ethan Mollick se me ha encendido la bombillita de por qué no me cuadra. Si pienso en mi universidad como una organización (de las leeeeeentas en reaccionar), donde los cambios requieren muchos meses (o años). No solo porque es pública… es que, sobre todo, es muy grande (trabajan unas 5.000 personas e influyen en los órganos de gobierno los representantes de 35.000), y tiene una cultura débil, o mejor dicho, muchas culturas fuertes incompatibles entre sí, desarrolladas en silos. Entonces, una tecnología que avanza en ciclos de muy pocos meses liberando capacidades nuevas (y casi inimaginables unos meses o semanas antes), que impactan considerablemente en la función y objetivos de la organización, nos lleva a la cuestión clave a la que apunta Ethan y que también le he escuchado a David Roldán Martínez: La pregunta relevante no es “cuáles son las capacidades de los modelos”, sino quién (o quiénes) en la organización tiene la autoridad y la capacidad para revisar, establecer e implementar las medidas de protección (o de aprovechamiento de la oportunidad) cada 4 o 5 meses. Me da la sensación (igual me equivoco) que la gente que conozco está anclada en la primera pregunta. Quizás porque la respuesta a la segunda pregunta es desgraciadamente obvia: NADIE.
Tres años siendo el niño del cuento (y por fin sé por qué)
Esta semana lo he probado yo mismo aplicado al Grado de Ingeniería de Organización Industrial. El jueves voy a ponerlo en práctica con unos 35 asistentes al taller y veremos qué pasa. Hasta ahora solo lo he aplicado a mis propias asignaturas, que no es exactamente una muestra imparcial.
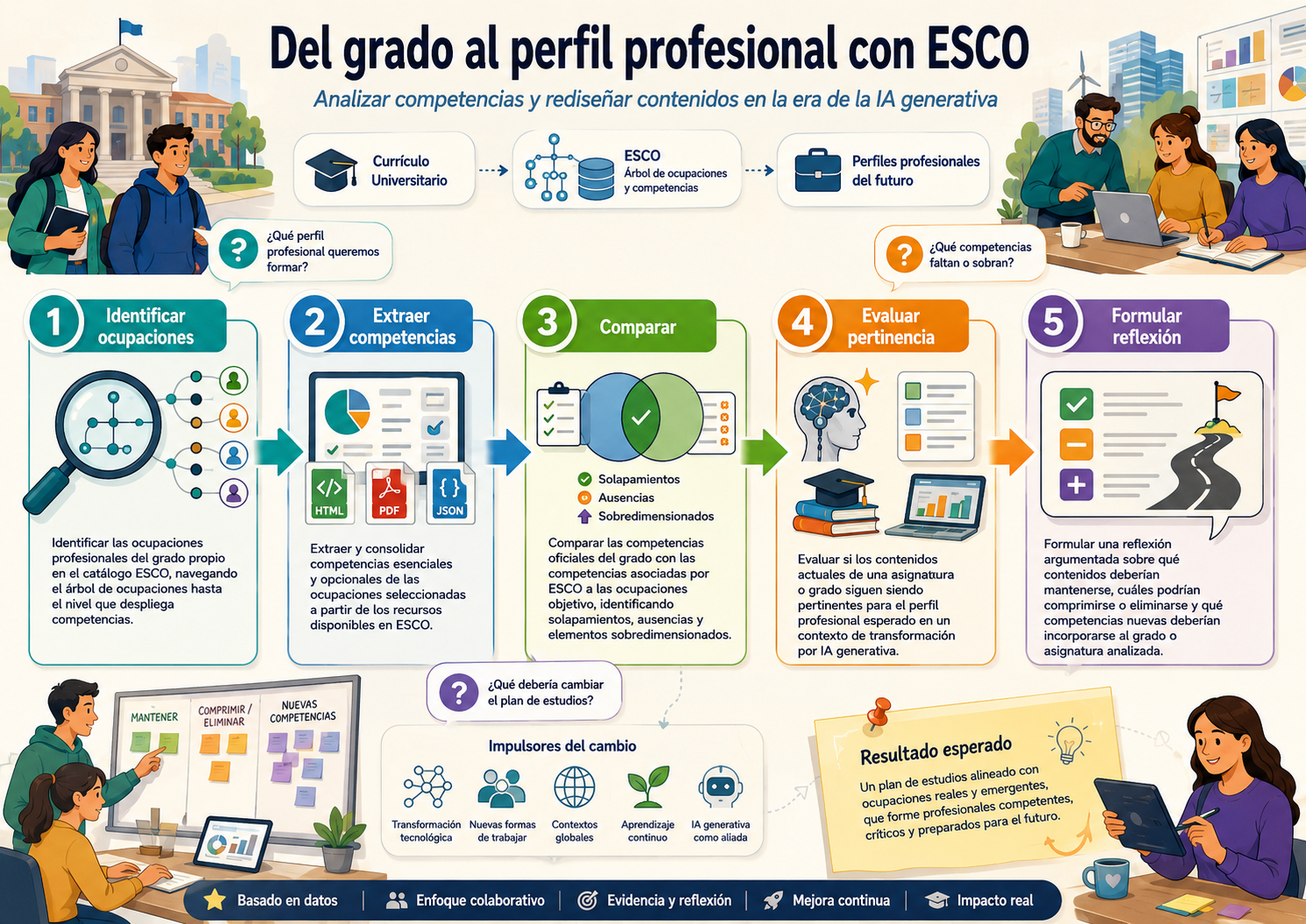
European Commission. Directorate General for Employment, Social Affairs and Inclusion. (2019). ESCO handbook: European skills, competences, qualifications and occupations. Publications Office. atlasTI-ART-639 soft Skills. https://data.europa.eu/doi/10.2767/934956
RESULTADOS–> [en construcción]
Esa metodología me permitirá activar un proyecto atascado sobre soft-skills
Te propongo que uses la iconografía para reflexionar sobre qué es para ti aprender en la universidad actual.
Iconografía: estudio, descripción y clasificación de imágenes o símbolos, analizando el significado de las representaciones visuales
Yo estaba eligiendo una imagen para ilustrar una diapositiva de una presentación y, mientras dudaba entre las tres imágenes que te muestro abajo, me he dado cuenta de que mis dudas reflejaban matices de lo que me chirriaba o me encajaba. He estado unos 15 minutos analizando los símbolos y lo que me evocan. Al final me he decantado por una de ellas. Pero lo importante es lo que me ha hecho reflexionar mientras elegía. No voy a desvelarte mi reflexión para no contaminar la tuya. Te comparto el ejercicio porque, para mí, ha resultado inspirador.
¿Qué imagen representa mejor para ti el aprendizaje en la universidad? ¿Por qué?
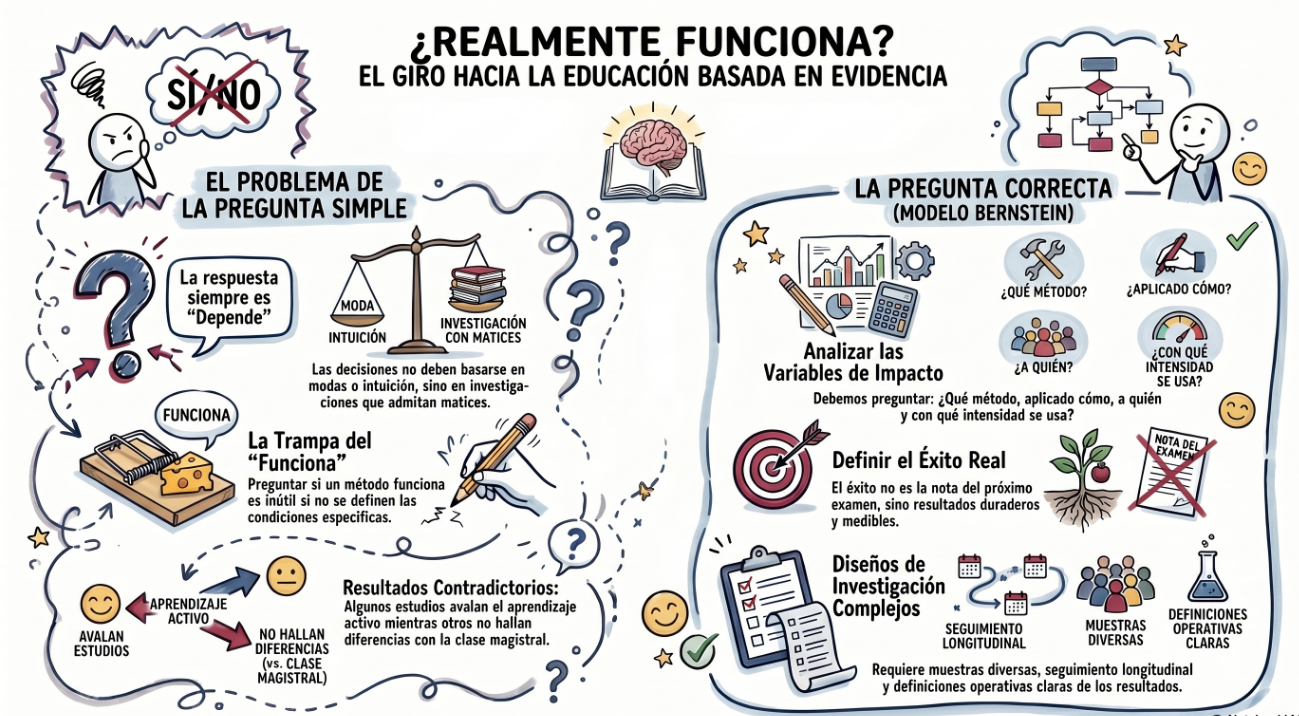
¿Qué es evidence-based?, dices mientras clavas en mi pupila tu pupila azul. Voy a aprovechar el resumen de un artículo de investigación en educación superior para dar una respuesta que sirva tanto para management en general, como para recursos humanos, como para dirección de operaciones, o para educación superior. Para cualquier campo donde alguien quiera tomar decisiones apoyándose en investigación en lugar de en intuición o moda.
Bernstein, D. A. (2018). Does active learning work? A good question, but not the right one. Scholarship of Teaching and Learning in Psychology, 4(4), 290–307. http://dx.doi.org/10.1037/stl0000124
En los años 50 el debate era “¿funciona la terapia?”, y la pregunta resultó ser inútil, porque la única respuesta posible es “depende”. Con el aprendizaje activo estamos en el mismo sitio: hay estudios que dicen que sí, otros que dicen que más o menos, y otros que no encuentran diferencias con la clase magistral. Bernstein propone que dejemos de preguntarnos si “funciona” y empecemos a preguntar : ¿qué tipo de aprendizaje activo, aplicado cómo, a quién, con qué nivel de intensidad y adherencia, produce qué tipo de resultados y durante cuánto tiempo?
El problema es que responder a ese tipo de preguntas es bastante difícil. Requiere diseños más complejos, muestras diferentes, seguimiento longitudinal, y una definición operativa de “funciona” que no sea la nota del examen de la semana siguiente. No es lo que la mayoría de los papers de docencia hacen (ni los de management).
Pero ese es precisamente el trabajo que debemos hacer: el que responde preguntas que importan de verdad.
Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
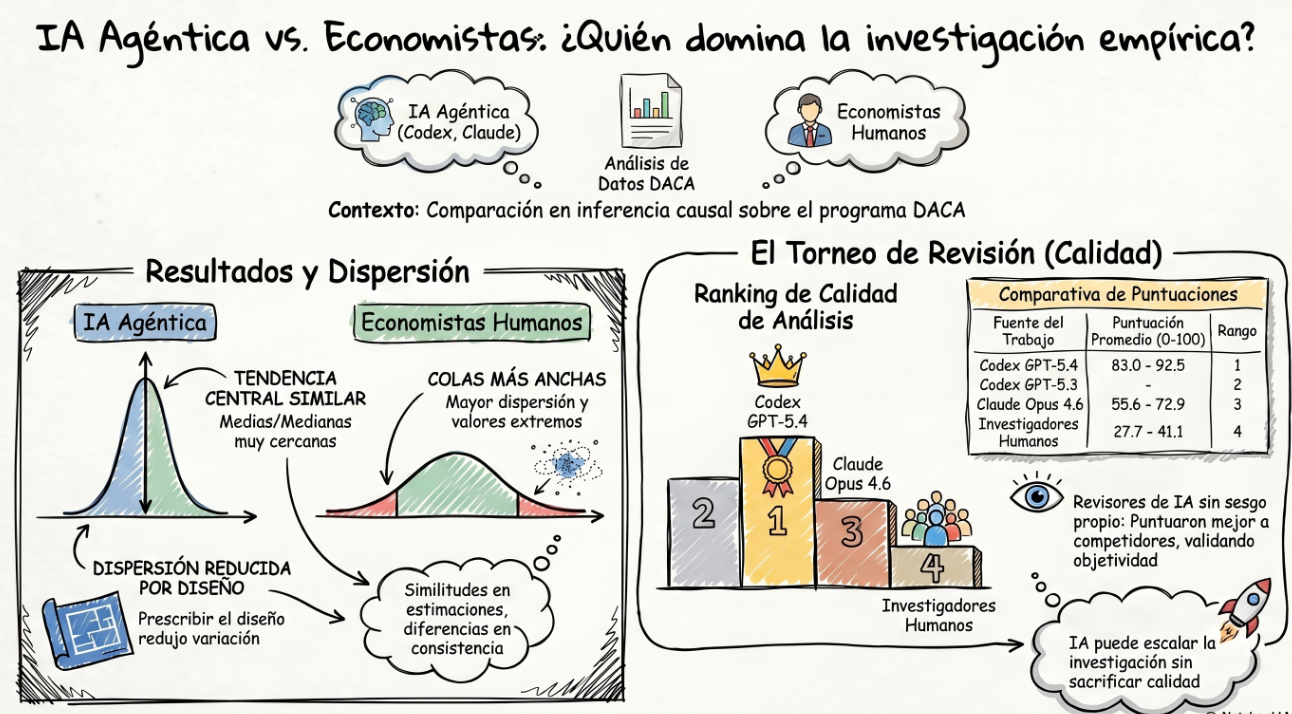
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
Humanos no ponderados: mínimo −4,9 y máximo 66,0.
Humanos ponderados: mínimo −4,9 y máximo 66,0.
GPT-5.4: mínimo 1,4 y máximo 7,0.
GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.