#HowTo #ffmpeg #herramientas #productividad
Disclaimer: a mí siempre me ha gustado más trabajar con scripts que con menús y ventanas. Desde que hace unos 35 años empecé a usar SPSS, pasando por R y cualquier otro programa que me permita guardar un log de lo que he hecho como algo ejecutable en el futuro, me tienen robado el corazón. Así que esto que describo no es para todos los públicos.
Dicho esto: llevo años editando vídeos con Camtasia, MS Stream y otras aplicaciones. Funcionan bien. El problema no es solo que no puedas hacer batch. Es que algunas operaciones que parecen simples, en una herramienta con interfaz gráfica, se vuelven absurdamente lentas. Sacar diez fragmentos recortados de un vídeo en Camtasia puede costarte fácilmente dos horas: abrir el proyecto, marcar el inicio y el fin de cada fragmento, exportar, esperar el render y repetir si no ha salido como querías a la primera. Lo mismo con Adobe Premiere, Clipchamp, MS Stream, o cualquier otra herramienta con ventanas y botones. Están diseñadas para la edición creativa, para decidir qué hacer con un vídeo. No para procesar en volumen. No es un defecto, es que no es su caso de uso.
Si además tenemos en cuenta el tiempo de renderizado… Las herramientas con interfaz gráfica tienen que gestionar previsualización, efectos, capas… Aunque tú solo quieras cortar un fragmento. ffmpeg en local no tiene nada de eso; va directo al fichero y, en muchos casos, a una velocidad de vértigo.
El otro problema es la reproducibilidad. Si has tardado dos horas en sacar esos diez fragmentos y luego necesitas cambiar algo (el formato de salida, el punto de corte, lo que sea), vuelves a empezar casi desde cero. Con un script, cualquier modificación tarda solo segundos: cambias un parámetro, vuelves a ejecutar, y obtienes el resultado actualizado sobre todos los ficheros. Además, tienes por escrito exactamente qué has hecho, lo que no es fácil de recordar cuando ha pasado tiempo (aunque sea poco) desde que lo hiciste.
Este fin de semana he integrado ffmpeg a mi espacio de trabajo (es un año con intensas novedades: migrar de Ennote a Zotero, empezar con Obsidian, pasar de Jira a Clockify…). ffmpeg es una herramienta de línea de comandos (gratuita, de código abierto) que procesa vídeo y audio en local y acepta scripts. Puedes dividir un vídeo en fragmentos por tiempo, comprimir, cambiar de formato, extraer audio, recortar o concatenar, y hacerlo en modo batch sobre los ficheros de una carpeta entera sin tocar nada manualmente.
Cómo instalarlo en Windows
- Descarga la versión compilada desde https://ffmpeg.org/download.html (sección Windows, yo he usado la build de gyan.dev).
- Descomprime el .zip
- Localiza el ejecutable que necesitas es
ffmpeg.exe, que está dentro de la subcarpetabin. No hace falta instalarlo ni tocar el PATH si elffmpeg.exeestá en la misma carpeta donde tienes los scripts y lo llamas como.\ffmpeg.exe. - Si prefieres añadir la carpeta donde este el .ex al PATH para poder ejecutarlo desde cualquier carpeta tambien es una opcion (yo no la uso).
Los scripts: PowerShell + .bat
Yo escribo los scripts en PowerShell (.ps1) porque es más legible para lógica con bucles y condiciones. El único problema es que hacer doble clic en un .ps1 no lo ejecuta directamente en Windows debido a la política de ejecución por defecto. La solución es crear un fichero .bat que lo llame:
@echo off
powershell.exe -ExecutionPolicy Bypass -File "%~dp0tu_script.ps1"
pause
Con ese .bat en la misma carpeta que el .ps1, los videos y el ffmepg.exe haces doble clic y se ejecuta. El %~dp0 es la ruta de la carpeta donde está el .bat (así no depende de desde dónde lo lances), y el pause al final mantiene la ventana abierta para que puedas ver si ha habido algún error.
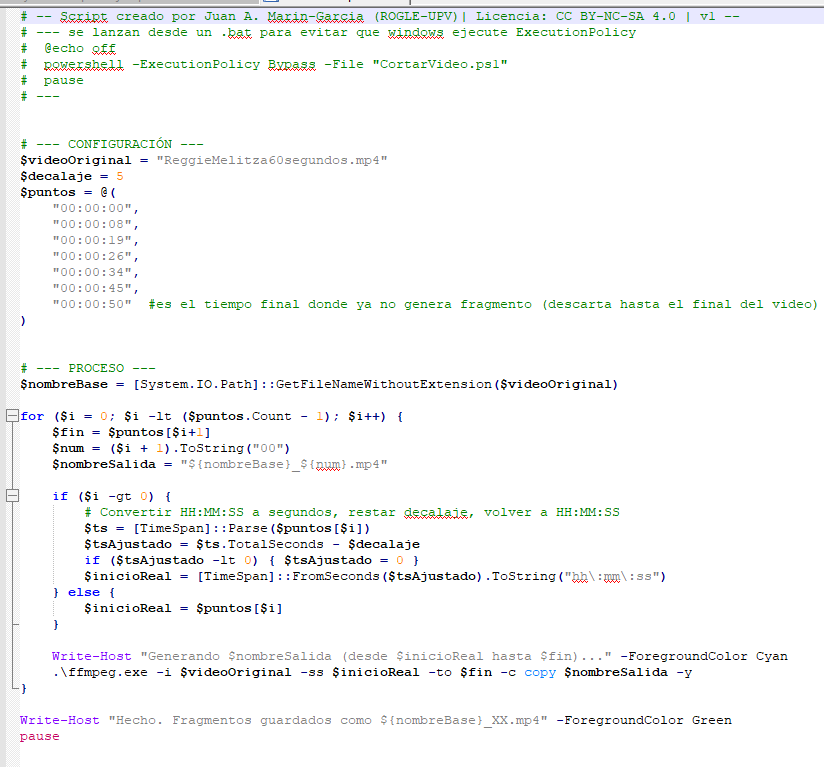
Un script básico que procesa todos los .mp4 de la carpeta actual tiene esta estructura:
$carpeta = Split-Path -Parent $MyInvocation.MyCommand.Path
$videos = Get-ChildItem -Path $carpeta -Filter "*.mp4"
foreach ($video in $videos) {
$entrada = $video.FullName
$salida = Join-Path $carpeta ("procesado_" + $video.Name)
& ffmpeg -i $entrada [tus opciones aquí] $salida
}
Ajustas [tus opciones aquí] a lo que necesites y el script recorre todos los vídeos de la carpeta sin que tengas que hacer nada más.
El balance
Me costó unas dos horas montarme los scripts (era novato en ffmpeg y parte del tiempo fue entender qué opciones hacen qué). Ya me han ahorrado aproximadamente seis horas de trabajo este fin de semana en tareas que hago con regularidad. El retorno empieza a ser positivo, y va a seguir siéndolo cada vez que los reutilice.
Camtasia y similares no va a desaparecer de mi flujo para ediciones más elaboradas. Pero para procesar en batch, para tareas que se repiten, o simplemente para no perder una tarde haciendo a mano algo que dura treinta segundos en un script, merece la pena la inversión inicial.
Visitas: 32