Cuando la tecnología avanza en meses y la institución en años
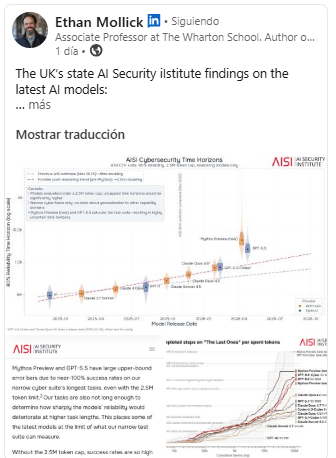
Llevo como 3 años teniendo la intuición de que el modo en que “la gente” aborda el asunto de la IA gen en la universidad no me convence (los tipos de controles que plantean, los enfoques subyacentes, que son prácticamente reactivos, etc.). No sabía hacer explícito por qué me chirriaba tanto, simplemente tenía el síndrome del niño de “El traje nuevo del emperador” del cuento de H.C. Andersen. Hasta hoy. Gracias a este post de Ethan Mollick se me ha encendido la bombillita de por qué no me cuadra. Si pienso en mi universidad como una organización (de las leeeeeentas en reaccionar), donde los cambios requieren muchos meses (o años). No solo porque es pública… es que, sobre todo, es muy grande (trabajan unas 5.000 personas e influyen en los órganos de gobierno los representantes de 35.000), y tiene una cultura débil, o mejor dicho, muchas culturas fuertes incompatibles entre sí, desarrolladas en silos. Entonces, una tecnología que avanza en ciclos de muy pocos meses liberando capacidades nuevas (y casi inimaginables unos meses o semanas antes), que impactan considerablemente en la función y objetivos de la organización, nos lleva a la cuestión clave a la que apunta Ethan y que también le he escuchado a David Roldán Martínez: La pregunta relevante no es “cuáles son las capacidades de los modelos”, sino quién (o quiénes) en la organización tiene la autoridad y la capacidad para revisar, establecer e implementar las medidas de protección (o de aprovechamiento de la oportunidad) cada 4 o 5 meses. Me da la sensación (igual me equivoco) que la gente que conozco está anclada en la primera pregunta. Quizás porque la respuesta a la segunda pregunta es desgraciadamente obvia: NADIE.
Tres años siendo el niño del cuento (y por fin sé por qué)
Esta semana lo he probado yo mismo aplicado al Grado de Ingeniería de Organización Industrial. El jueves voy a ponerlo en práctica con unos 35 asistentes al taller y veremos qué pasa. Hasta ahora solo lo he aplicado a mis propias asignaturas, que no es exactamente una muestra imparcial.
European Commission. Directorate General for Employment, Social Affairs and Inclusion. (2019). ESCO handbook: European skills, competences, qualifications and occupations. Publications Office. atlasTI-ART-639 soft Skills. https://data.europa.eu/doi/10.2767/934956
RESULTADOS–> [en construcción]
Esa metodología me permitirá activar un proyecto atascado sobre soft-skills
Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
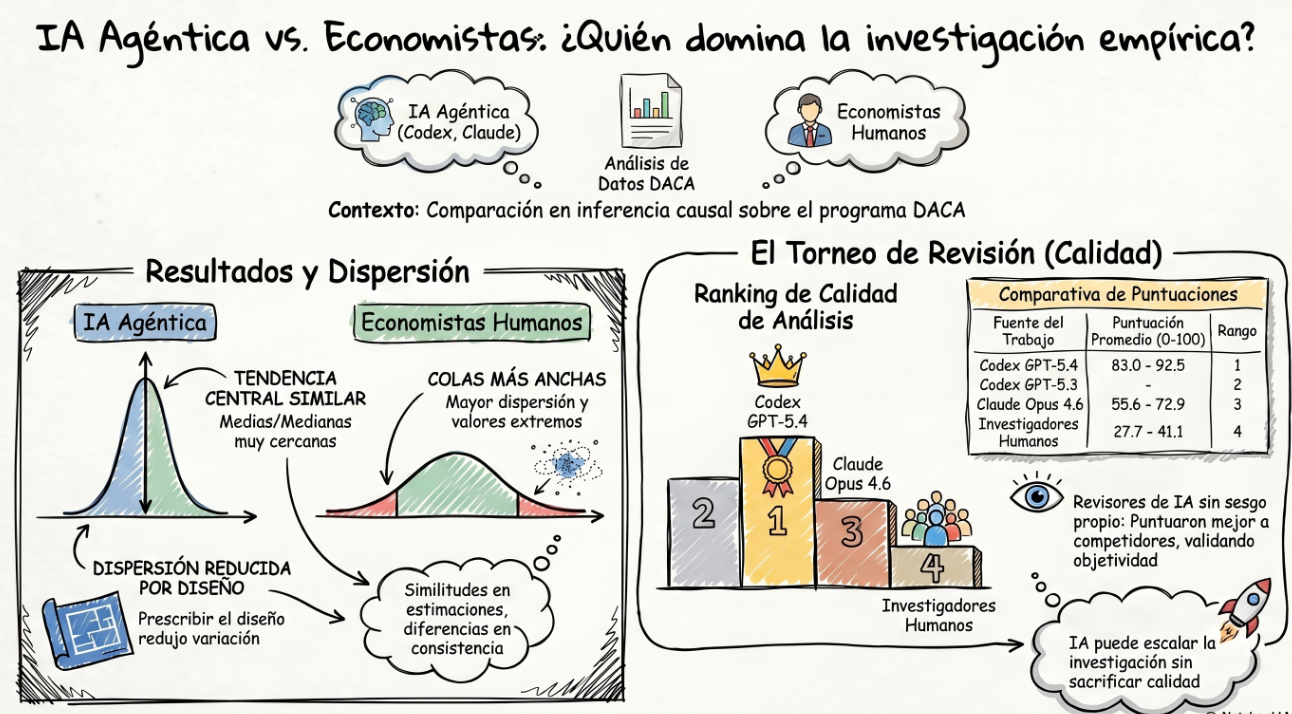
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
Humanos no ponderados: mínimo −4,9 y máximo 66,0.
Humanos ponderados: mínimo −4,9 y máximo 66,0.
GPT-5.4: mínimo 1,4 y máximo 7,0.
GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.
Que el mundo profesional ha cambiado en los últimos años está fuera de toda duda. La pandemia de COVID-19 y la irrupción de la IA generativa se han sumado a otros cambios que ya se estaban manifestando.
En este contexto, creo que es necesario replantear qué competencias/skills necesitamos formar en nuestros graduados. Quizás no sean necesarios cambios (lo dudo); quizás haya que añadir cosas nuevas; quizás algunas cosas hayan pasado a ser obsoletas. Pero no es trivial dar respuesta a las preguntas: ¿debemos actualizar la formación que ofrecemos? ¿en qué sentido?
Llevo casi dos años dándole vueltas a esto, pero aún no he logrado concretar un marco de trabajo. Entre otras cosas, estaba esperando encontrar alguna investigación que explicara cómo ha cambiado el trabajo profesional en algunas profesiones debido al teletrabajo y otras formas de flexibilidad, la inteligencia artificial generativa y demás condiciones actuales.
Hoy he decidido crearme un “framework” que no estoy seguro de que me lleve a buen puerto, pero lo comparto, lo intento poner en marcha y luego os comento si me ha funcionado o no.
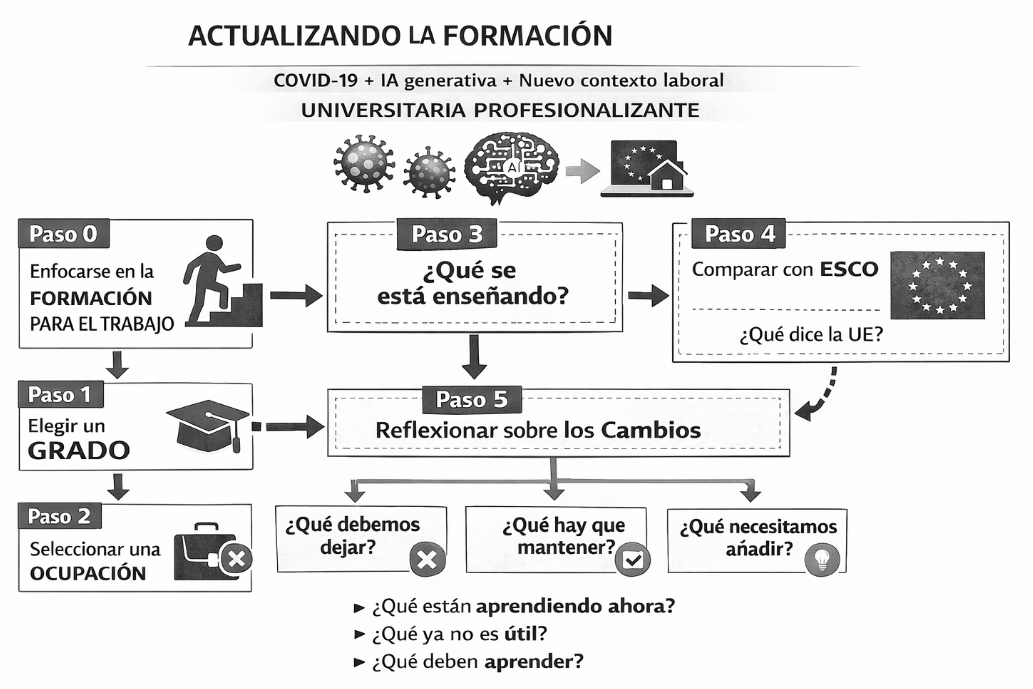
Paso 0. Decido centrarme en la formación para el trabajo y en ver las necesidades de la persona que usará lo aprendido para ser una profesional. Podría haber elegido otro enfoque, pero creo que este me va a resultar más sencillo y luego por abstracción intentar generalizar hacia otros perfiles.
Paso 1. Elegir un grado para centrarme en él.
Pensar en qué cambios son necesarios a nivel global me resulta demasiado complicado, ya que el impacto del nuevo contexto puede ser muy distinto en cada profesión. Igual luego no lo son tantos, pero me ha parecido más sencillo ir de lo particular a lo general que al revés.
Paso 2. Elegir una ocupación dentro de las que se suponen más comunes afines al grado y centrarme en ella, para luego ir abriendo el abanico a algunas ocupaciones parecidas y ver si hay cambios sustanciales.
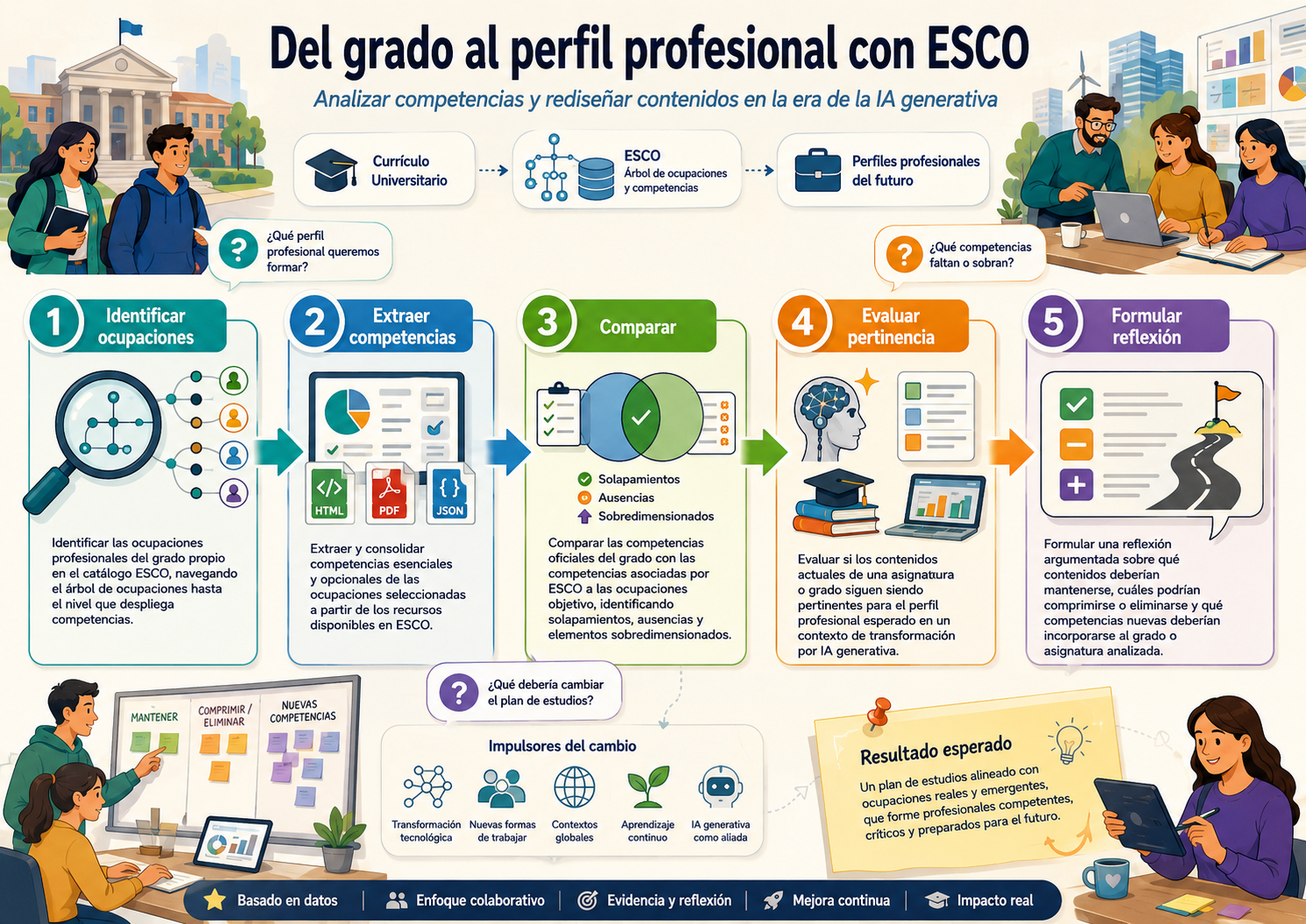
Paso 3. Identificar cuáles son las competencias en las que estamos formando actualmente. Es un paso sencillo porque la “verdad” es lo que consta en las memorias de verificación de cada título.
Paso 4. Comparar el resultado del paso 3 con las propuestas oficiales de la Unión Europea.
yo he decidido usar como marco de referencia ESCO. Quizás haya otros marcos mejores, pero este es el que conozco y, en teoría, debería ser un marco sólido.
No obstante, las propuestas de ESCO están ancladas en el pasado. En el mejor de los casos, son buenas propuestas para hace 5 años y tendremos que reflexionar si siguen vigentes o no.
Paso 5. Integrar los resultados de los Pasos 3 y 4 y reflexionar sobre qué cambios son necesarios.
La parte de reflexión la tengo un poco débil. En un mundo ideal, donde las empresas supieran de verdad en qué ha cambiado realmente lo que sus profesionales necesitan, el informante relevante sería la empresa. Pero no estoy muy seguro de que haya alguna que tenga la certeza absoluta de qué es lo que realmente necesitan hoy, ni de qué necesitarán dentro de 5 años. Porque la IA generativa (que es el factor de contexto más influyente actualmente) está en pleno “hype” y poca gente puede tener certeza de dónde, cuándo y cómo va a acabar.
Independientemente de quiénes sean los informantes (ya conseguiré aclararme o usar “muestras de conveniencia” o pedir opinión a mis compañeros académicos para que hagamos el diseño desde nuestras “torres de marfil”), las preguntas clave son:
¿Qué están aprendiendo ahora?
¿Qué deberían dejar de aprender porque no es útil?
¿Qué cosas nuevas deberían empezar a aprender porque las necesitarán para ser buenas profesionales?
European Commission. Directorate General for Employment, Social Affairs and Inclusion. (2019). ESCO handbook: European skills, competences, qualifications and occupations. Publications Office. atlasTI-ART-639 soft Skills. https://data.europa.eu/doi/10.2767/934956
I will be presenting this research at the upcoming XVII International Workshop ACEDEDOT – OMTECH 2026, taking place in Almería, Spain, from March 12-14, 2026:
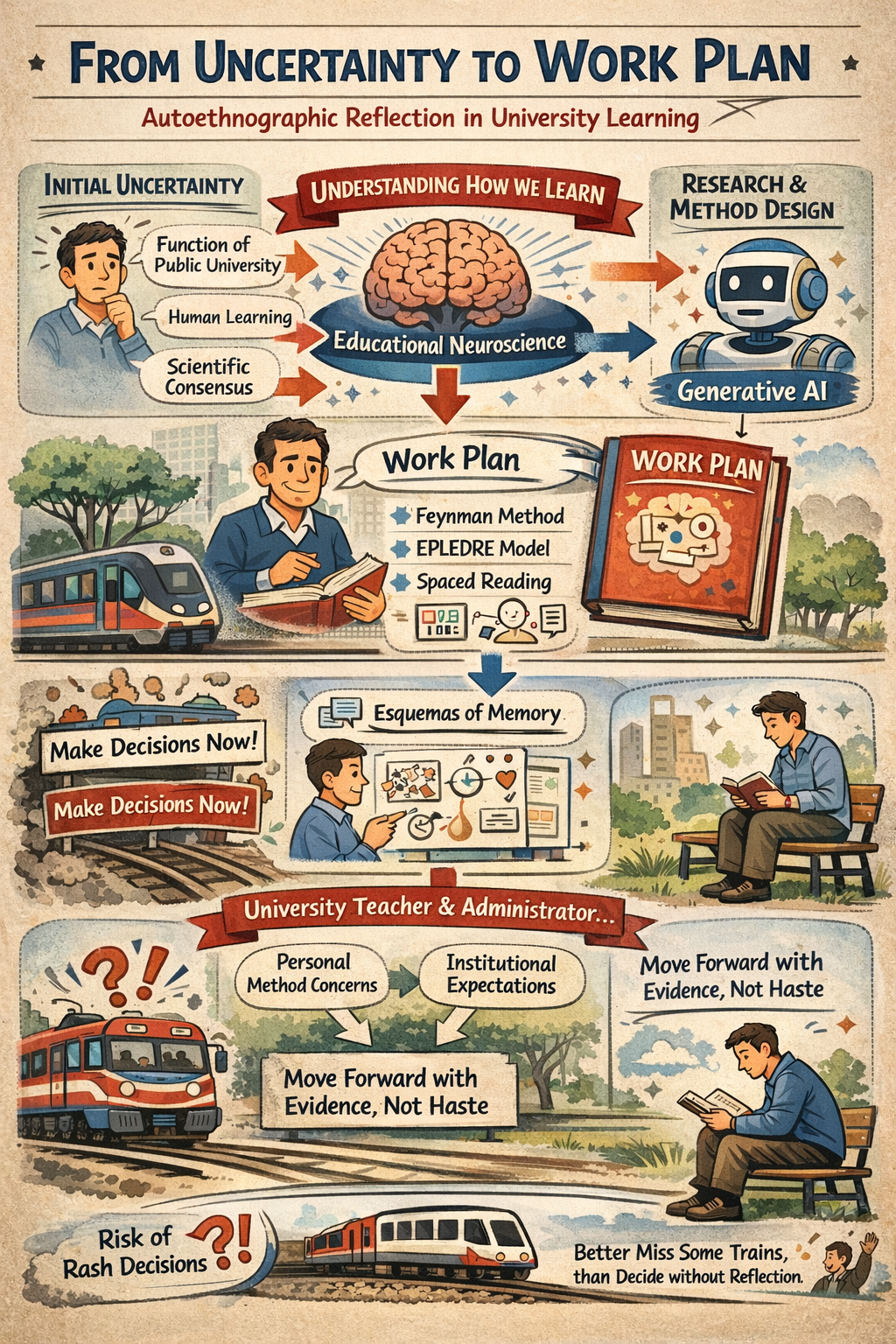
This communication presents an autoethnographic reflection. Building on four fundamental premises about the function of Spanish public universities and the established mechanisms of human learning, the author documents his personal journey from initial uncertainty to the design of a systematic work plan. The study focuses on understanding the current scientific consensus on how learning is consolidated in the brain and exploring the possibilities of generative AI to enhance this process in the university context. Drawing on the work of Héctor Ruiz Martín, a work plan is designed that combines recommendations from educational neuroscience with the Feynman method and the EPLEDRE model, including spaced reading, creation of sketchnote-type graphic schemes from memory, and public communication of the knowledge constructed. The communication shares the first graphic schemes developed and reflects on the author’s dual position as university teacher and administrator, facing both his own methodological uncertainties and institutional expectations for strategic guidance. It questions the “collective panic” surrounding the emergence of generative AI in universities and the pressure to make quick decisions without sufficient reflection. It proposes replacing reactive urgency with a deliberate process of calm, evidence-based reflection and pilot experimentation, recognizing that in contexts of accelerated change, it is preferable to miss some “trains” rather than make biased decisions under collective amygdala hijacking
Los LLM son aduladores y lisonjeros por naturaleza, tienes que pedirles que sean críticos o “destructivos” para intentar que hagan análisis más ecuánimes. Pero nunca tendrás la seguridad de que te detecten todos los errores o te manifiesten abiertamente todas las cosas negativas, sobre todo si están analizando una propuesta que es un bodrio sideral
Los LLM no tienen memoria a largo plazo. Cada plataforma tiene estrategias distintas para lidiar con el problema de superar la ventana de contexto. ChatGPT usa un FIFO (que, si estás conversando de manera iterativa profundizando sobre el mismo concepto, te da buen resultado porque realmente lo que importa es lo último en lo que estás trabajando). Claude hace “borrón y cuenta nueva”, pero antes, cuando detecta que se queda sin contexto, compacta la conversación (y la documentación subida), la guarda, inicia una nueva instancia y coge como punto de partida el resumen y, a partir de ahí, empieza a trabajar de nuevo. La forma en que trabaja CLAUDE es exactamente el modo que yo trabajo cuando tengo tareas con tiempo fragmentado (Que no puedo completar en una sesión de trabajo), por eso supongo que me gustan más los resultados que me da Claude que los de ChatGPT
Además de lo anterior, el uso de Skills y Agents permite aliviar el problema de la memoria de contexto. Solo se activa lo que necesitas para una tarea y, además, puedes activar “hilos” en paralelo (cada uno con su propia memoria de contexto libre para ese hilo) que se comunican entre sí (los resultados de unos son las entradas para otros). Es una forma modular y analítica de resolver tareas (algo que yo también hago de manera natural: divido en subtareas que me caben en tiempo fragmentado y guardo la “preparación” intermedia para alimentar otras tareas)
He tenido que rebuscar un poco para clarificar los conceptos de skill y agent, este es mi resumen:
Skill (instrucciones/prompts y herramientas para realizar una tarea concreta)
Instrucción: descripción de cuándo usar el skill (ej. “Usa esto cuando la usuaria pregunte por X”)
Herramienta: un trozo de código, una API o una función (ej. buscar en Google, calcular una hipoteca)
Agent (deciden (razonar, planificar) qué herramienta usar, en qué orden las usan y qué hacer si algo sale mal). Puedes activar varios agentes en paralelo
Sigue un ciclo o un proceso: Analiza la meta: “¿Qué me han pedido?”; Planifica: “¿Qué pasos necesito y qué Skills debo usar?”; Ejecuta: Usa una Skill; Observa: “¿El resultado es lo que esperaba?”; Itera: Repite hasta terminar
Imagen generada con Gemini nano bananaImagen generada con ChatGPT5.2
En unas jornadas en noviembre 2025 se me ocurrió preguntar si conocían el significado de algunos términos que, para mí, son básicos sobre IA generativa (si no sabes lo que significan dudo mucho que puedas entender cómo funciona y mucho menos pilotarla adecuadamente)
Asistieron unas 50 personas, todas ellas profesoras de universidad, en diferentes titulaciones y departamentos y con diferente trayectoria académica – desde jóvenes recién entradas a catedráticas -, y con cierta sensibilización y práctica como usuarias de Inteligencia Artificial Generativa (no creo que se pudieran considerar “novatas” o que acabaran de descubrir qué es esto de la IAgen).
Y estos son los resultados:
User prompt
(Lo que tú me dices)
Es como cuando tú haces una pregunta o pides algo. Por ejemplo, “cuéntame un cuento” o “ayúdame con mi tarea”. Es lo que TÚ escribes para hablar la IAgen
System prompt
(Las reglas secretas que tengo)
Es como las reglas que los programadores dieron a la IAgen antes de que pudiéramos hablar. Por ejemplo, “sé amable”, “ayuda siempre”, “no digas groserías”. Tú no puedes ver estas reglas, pero la IAgen siempre las sigue
En algunos casos (proyectos, “chat builder” o uso del LLM por API con un script ) puedes “controlar” el System prompt (añadirlo al programado o, en algunos modelos, sustituir el programado)
Temperature
(Qué tan creativo soy)
Imagínate que la IAgen tenga un botón de creatividad. Si está en “frío”, siempre da respuestas muy parecidas y serias. Si está en “caliente”, es más divertida, creativa, impredecible, pero a veces digo cosas raras. Es como elegir entre ser muy formal o muy juguetón
Context
(Lo que recordamos de nuestra conversación)
Es como nuestra memoria de la conversación. Si le dijiste a la IAgen que te gusta el helado de chocolate, lo recuerda para seguir hablando contigo sobre eso. Es todo lo que hemos dicho antes en nuestra charla (hasta el límite que los programadores hayan establecido)
La nueva información sustituye a la más antigua cuando sobrepasa la capacidad y se desborda (olvidando primero lo más antiguo)
Algunas plataformas (como POE) te permiten indicar a ti la amplitud del contexto
RAG
(Buscar información extra)
Es como cuando no sé algo y voy a buscar en una biblioteca especial para darte mejor información. En lugar de solo usar lo que ya sé, voy a buscar datos frescos para ayudarte mejor (uso los Chunk Embeedings para esto)
Chunk Embeedings
(Pedacitos de información organizados)
Imagínate que tienes muchos libros y cortas cada página por cada párrafo. Luego, cada párrafo lo conviertes en un vector (una lista de números). Así la IAgen puede encontrar el párrafo que necesito cuando preguntas algo. Por menos distancia con la pregunta
Embeddings
Imagínate que quieres describir a tu mejor amigo. Podrías decir:
Lo alto es (del 1 al 10)
Lo divertido es (del 1 al 10)
Lo bueno es en matemáticas (del 1 al 10)
Lo deportista es (del 1 al 10)
Entonces, tu amigo sería algo como: [7, 9, 5, 8] – esos son 4 números que lo describen-.
Ahora imagínate que en lugar de 4 cosas, quisieras describir TODAS las características posibles de tu amigo: su humor, inteligencia, creatividad, bondad, si le gustan los animales, si es tímido, si le gusta la música… podrían ser 300 o 1000 características diferentes
Eso es exactamente lo que hace un embedding con las palabras. Toma una palabra como “gato” y la convierte en una lista súper larga de números (como [0.2, -0.5, 0.8, 0.1, -0.3…]) donde cada número representa una característica de esa palabra.
La palabra “perro” tendría números muy parecidos a “gato” porque ambos son animales peludos y mascotas. Pero “avión” tendría números muy diferentes.
Vector n-dimensional
Es el nombre técnico para esa lista súper larga de números. Si tiene 300 números, decimos que es un “vector de 300 dimensiones”. Es como si cada palabra viviera en un espacio gigante con 300 direcciones diferentes, y el vector representa las coordenadas que nos dicen dónde está exactamente en ese espacio.
Por eso las palabras parecidas “viven cerca” en ese espacio invisible y las diferentes “viven lejos”.
Distance (cosine)
Una forma de medir la distancia donde lo que importa es la dirección (no la distancia “euclídea”). Si los vectores apuntan en la misma dirección tienen menos distancia (aunque uno sea más corto o más lejano)
NLP
(Entender el lenguaje humano)
La capacidad de la IAgen para entender lo que se le dice y responderte en tu idioma. Es como ser un traductor súper inteligente que entiende no solo las palabras, sino también lo que realmente quieres decir.
Sentence Transformers vs GPT (Dos tipos diferentes de robots inteligentes)
Sentence Transformers
Una especie de robots que son súper buenos para entender y comparar frases. Son como bibliotecarios que pueden encontrar el libro que “CREEN” que buscas a partir de una información incompleta que les das. Convierten el texto en números (y siempre los mismos números para el mismo texto) en base a los pesos de su entrenamiento. Convierten frases nuevas en embeddings en tiempo real. Cuando les das una frase que nunca han visto antes, la procesan y crean un vector nuevo específicamente para esa frase completa.
Su trabajo es crear representaciones numéricas de frases completas
Son especialistas en capturar el significado de oraciones enteras
Generative Pretrained Transformers
Una especie de robots súper buenos para crear y escribir cosas nuevas. Durante el entrenamiento, ya se calcularon y “congelaron” todos los embeddings de los tokens. Cuando tú escribes algo, tus palabras se convierten en tokens, cada token ya tiene su embedding calculado, Los pesos de todas las conexiones también estaban ya calculados. Solo se comparan los embeddings para seleccionar los que tienen más probabilidad de continuar la secuencia
Durante el entrenamiento fue como afinar cada tecla del piano y ajustar cada cuerda. Ahora, cuando “tocas” una secuencia de teclas (escribes), el piano ya sabe qué sonidos hacer porque ya está todo afinado. Lo que ocurre es que a partir de unas instrucciones que le das (system + user prompts) el piano se dedica a componer e interpretar.
Attention mechanism
Es como cuando lees un cuento y prestas más atención a las partes importantes. Los GPT hacen lo mismo con las palabras: ponen más atención a las palabras que creen que son más importantes de tu pregunta, para darte una “mejor” respuesta.
El otro día me enteré de que hay empresas que subcontratan por completo sus memorias de sostenibilidad a consultoras externas. Y no me refiero a buscar apoyo técnico o asesoramiento, sino a delegar absolutamente todo el proceso. Esto me hizo reflexionar sobre un patrón que ya he visto repetirse con mucha frecuencia.
La lógica inicial es aparentemente sólida: cuando surge una nueva normativa que obliga a elaborar memorias sobre cualquier tema relevante (sostenibilidad, igualdad, transparencia, gestión de títulaciones, etc.), la idea detrás de la normativa es estimular la reflexión. El ejercicio de analizar qué hacemos, por qué lo hacemos y cómo podríamos hacerlo mejor debería ser una oportunidad de crecimiento y mejora continua. Sin embargo, cuando estas normativas llegan impuestas desde arriba, muchas organizaciones no las perciben como una oportunidad, sino como una carga burocrática, algo que etiquetan como No-Valor-Añadido-No-Evitable.
¿Cómo funciona la cadena de la externalización? Pues la verdad es que con un proceso bastante absurdo: la empresa contrata a una consultora (o un becario-a) para que busque los datos (o los invente, da igual), elabore un análisis con esos datos y redacte una memoria que cumpla con todos los requisitos legales. El objetivo no es aprender ni mejorar, sino simplemente evitar problemas regulatorios. La empresa que contrata ni siquiera lee el documento final.
Ahora estas consultoras (o estos becarios) están delegando todo el proceso (o toda la parte que pueden) a herramientas de inteligencia artificial generativa. El resultado es una farsa perfectamente orquestada: la empresa presenta memorias impecables, con una calidad de redacción como jamás había conseguido y un número impresionante de páginas. Los organismos auditores están satisfechos porque reciben más memorias que nunca, creyendo que están cumpliendo su misión de velar por la mejora en su área de responsabilidad.
Sin embargo, en todo este proceso no hay ni una sola neurona dedicada a pensar realmente en cómo mejorar o dónde pueden estar los problemas. La rueda sigue girando, pero ahora con muchas más personas implicadas, más gasto de energía y más dinero invertido en una actividad que ha perdido completamente su propósito original.
Mi Estrategia Personal
Frente a este panorama, he decidido adoptar una estrategia diferente. Voy a centrarme en encontrar usos para la IA generativa que me ayuden a aprender, a crecer intelectualmente y a explorar territorios que antes estaban fuera de mi alcance. Aprovecharé que la IA aún es relativamente barata porque las empresas necesitan nuestros datos para seguir entrenando sus modelos. Cuando se me acabe este chollo tecnológico, volveré tranquilamente a leer libros (o, dependiendo de la edad a la que me pille, a jugar a la petanca).
Si, además, consigo contagiar a alguien más para que use estas herramientas de manera inteligente, genial. Si no lo logro, tampoco me agobia. Lo importante es que yo voy a aprovechar esta oportunidad mientras dure.
Todo esto me recuerda a las clases de educación física en el colegio. A mí me encantaba dar vueltas al campo porque disfrutaba haciendo ejercicio. Algunos compañeros se escondían detrás de un árbol y aparecían solo en la última vuelta para que el profesor los viera llegar. Yo me lo pasaba muy bien corriendo, ellos se lo pasaban muy bien escondiéndose. Cada uno disfrutaba de la opción que había elegido. Nunca me importó que otros se escondieran (es más, me dejaban la pista más libre para correr a mi ritmo). Me habría fastidiado tener que esconderme y perder el tiempo en lugar de dar tres vueltas más al campo, pero nadie me impidió correr. Ahora creo que la situación es similar: puedo elegir cómo relacionarme con estas nuevas herramientas, independientemente de lo que hagan los demás.
Vivimos en una época en la que es fácil dejarse arrastrar por la corriente del mínimo esfuerzo y la externalización de todo lo que requiere pensamiento crítico. Pero también tenemos la oportunidad de usar estas mismas herramientas que otros emplean para evitar pensar, precisamente para pensar mejor y llegar más lejos. La elección, al final, es nuestra.
El problema no está en la tecnología en sí, sino en cómo decidimos relacionarnos con ella. Podemos usarla como una muleta para evitar el esfuerzo intelectual o como una palanca para amplificar nuestras capacidades de reflexión y aprendizaje. Yo tengo claro qué opción elijo.
En mis asignaturas, he definido una política para el uso de IA generativa y la comparto por si puede servir de referencia a otros colegas.
No me interesa valorar qué son capaces de hacer mis estudiantes como usuarios de IA generativa, sino fomentar que aprendan de verdad los contenidos o desarrollen actitudes o habilidades. Por eso, animo a emplear IA cuando les ayude a aprender, y desaconsejo su uso cuando se convierta en un atajo que impida el desarrollo de competencias.
En cada actividad especifico si se puede usar IA y en qué medida. Además, invito a los estudiantes a preguntar si tienen dudas. Esto evita ambigüedades y les ayuda a comprender el sentido pedagógico de cada decisión.
Adicionalmente he adaptado el modo en que entrego puntos por las tareas realizadas. Con el nuevo sistema pretendo desincentivar el juego absurdo de estar calificando un texto escrito por una IA e intentar dar feedback/feedforward a mis estudiantes basados en una quimera. Combino tareas observables en clase (evaluación continua (0-10)) con reflexiones personales que no aportan valor si se hacen con IA (evaluación dicotómica (hecho/no hecho)). El objetivo es que una reflexión breve y auténtica del estudiante tenga más valor pedagógico que una exposición extensa generada artificialmente
En una de mis charlas sobre uso de IA generativa para personal investigador salió el tema de cuanta Agua/energía consume el uso de IA generativa. Se comentó que alguien había leído que eran como varios litros de agua por cada imagen generada. A mí eso me pareció desorbitado, pero no tenía ninguna cifra o información que aportar. Se me ocurrían varias formas de estimarlo, aunque fuese de manera muy aproximada. Algunas de ellas eran por el método de “reducción al absurdo”, en otras llegué a barajar la posibilidad de montarme un modelo en local y medir el consumo…
The marginal energy used by a standard prompt from a modern LLM in 2025 is relatively established at this point, from both independent tests and official announcements. It is roughly 0.0003 kWh, the same energy use as 8-10 seconds of streaming Netflix or the equivalent of a Google search in 2008 (interestingly, image creation seems to use a similar amount of energy as a text prompt)1. How much water these models use per prompt is less clear but ranges from a few drops to a fifth of a shot glass (.25mL to 5mL+), depending on the definitions of water use (here is the low water argument and the high water argument).
[…]
It does not take into account the energy needed to train AI models, which is a one-time process that is very energy intensive. We do not know how much energy is used to create a modern model, but it was estimated that training GPT-4 took a little above 500,000 kWh, about 18 hours of a Boeing 737 in flight.








{kind=link}