¿Qué es evidence-based?, dices mientras clavas en mi pupila tu pupila azul. Voy a aprovechar el resumen de un artículo de investigación en educación superior para dar una respuesta que sirva tanto para management en general, como para recursos humanos, como para dirección de operaciones, o para educación superior. Para cualquier campo donde alguien quiera tomar decisiones apoyándose en investigación en lugar de en intuición o moda.
Bernstein, D. A. (2018). Does active learning work? A good question, but not the right one. Scholarship of Teaching and Learning in Psychology, 4(4), 290–307. http://dx.doi.org/10.1037/stl0000124
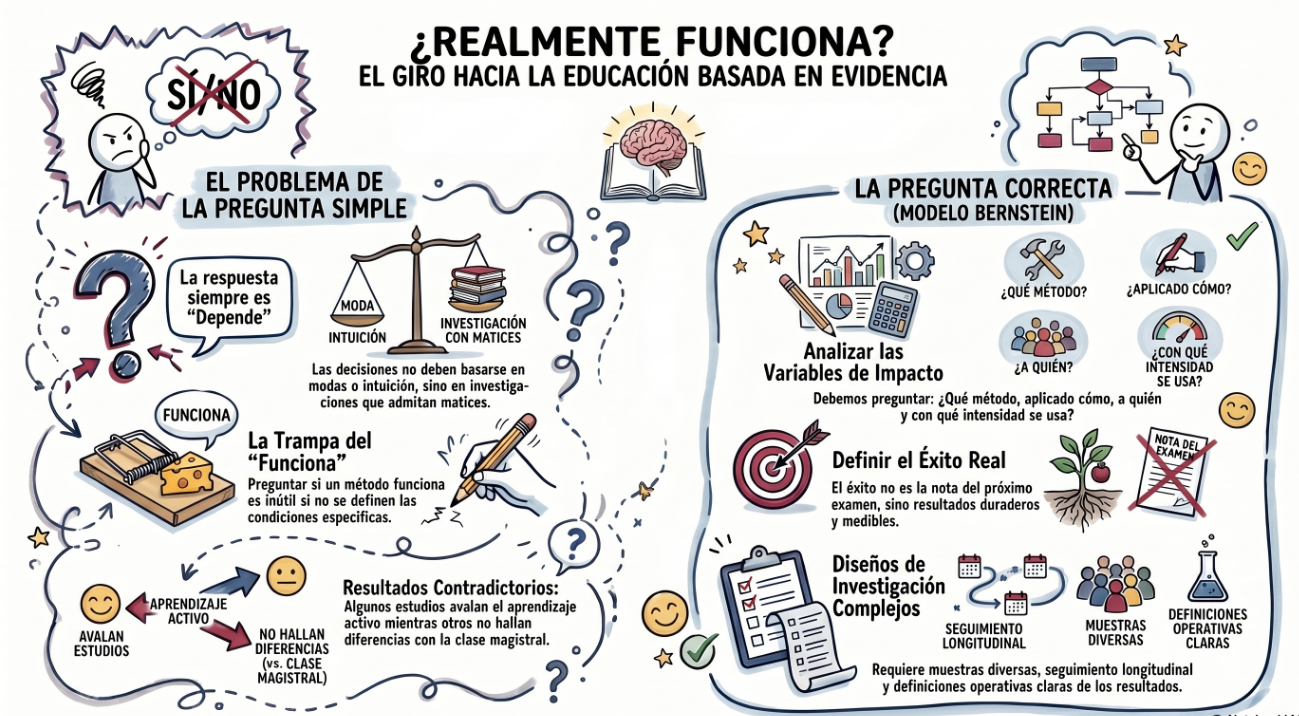
En los años 50 el debate era “¿funciona la terapia?”, y la pregunta resultó ser inútil, porque la única respuesta posible es “depende”. Con el aprendizaje activo estamos en el mismo sitio: hay estudios que dicen que sí, otros que dicen que más o menos, y otros que no encuentran diferencias con la clase magistral. Bernstein propone que dejemos de preguntarnos si “funciona” y empecemos a preguntar : ¿qué tipo de aprendizaje activo, aplicado cómo, a quién, con qué nivel de intensidad y adherencia, produce qué tipo de resultados y durante cuánto tiempo?
El problema es que responder a ese tipo de preguntas es bastante difícil. Requiere diseños más complejos, muestras diferentes, seguimiento longitudinal, y una definición operativa de “funciona” que no sea la nota del examen de la semana siguiente. No es lo que la mayoría de los papers de docencia hacen (ni los de management).
Pero ese es precisamente el trabajo que debemos hacer: el que responde preguntas que importan de verdad.
Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
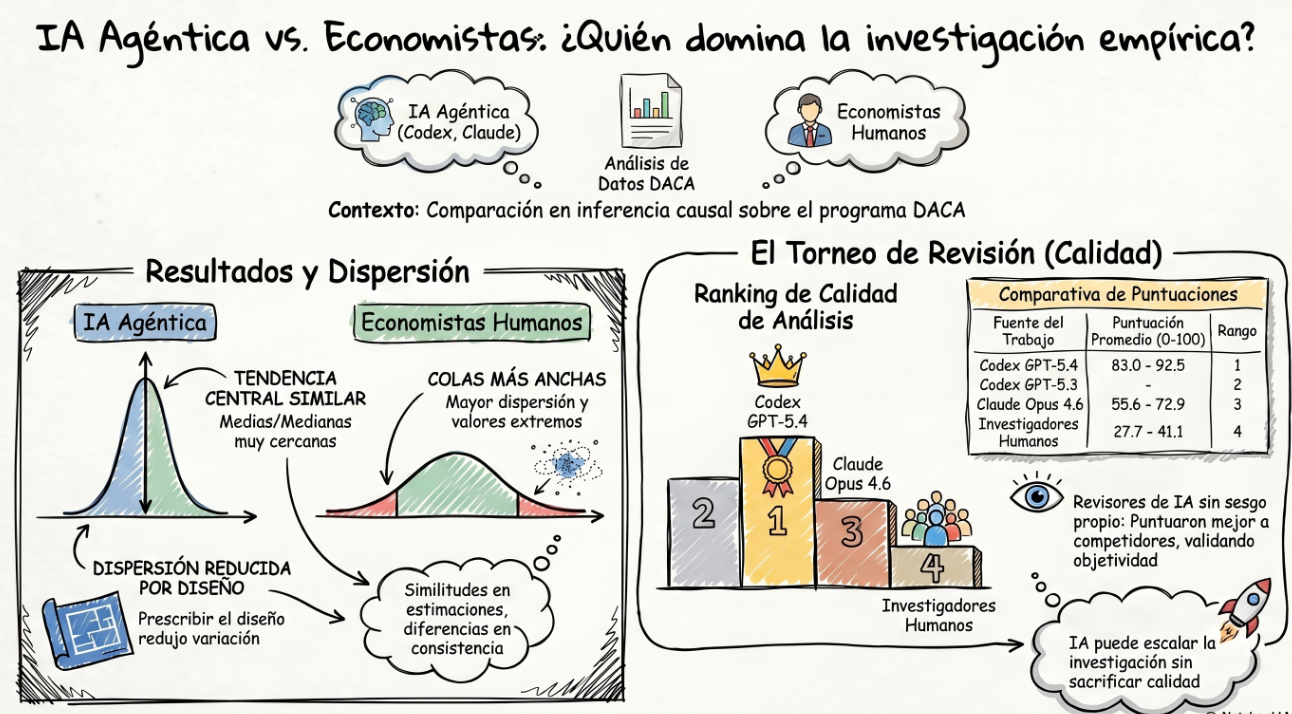
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
Humanos no ponderados: mínimo −4,9 y máximo 66,0.
Humanos ponderados: mínimo −4,9 y máximo 66,0.
GPT-5.4: mínimo 1,4 y máximo 7,0.
GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.
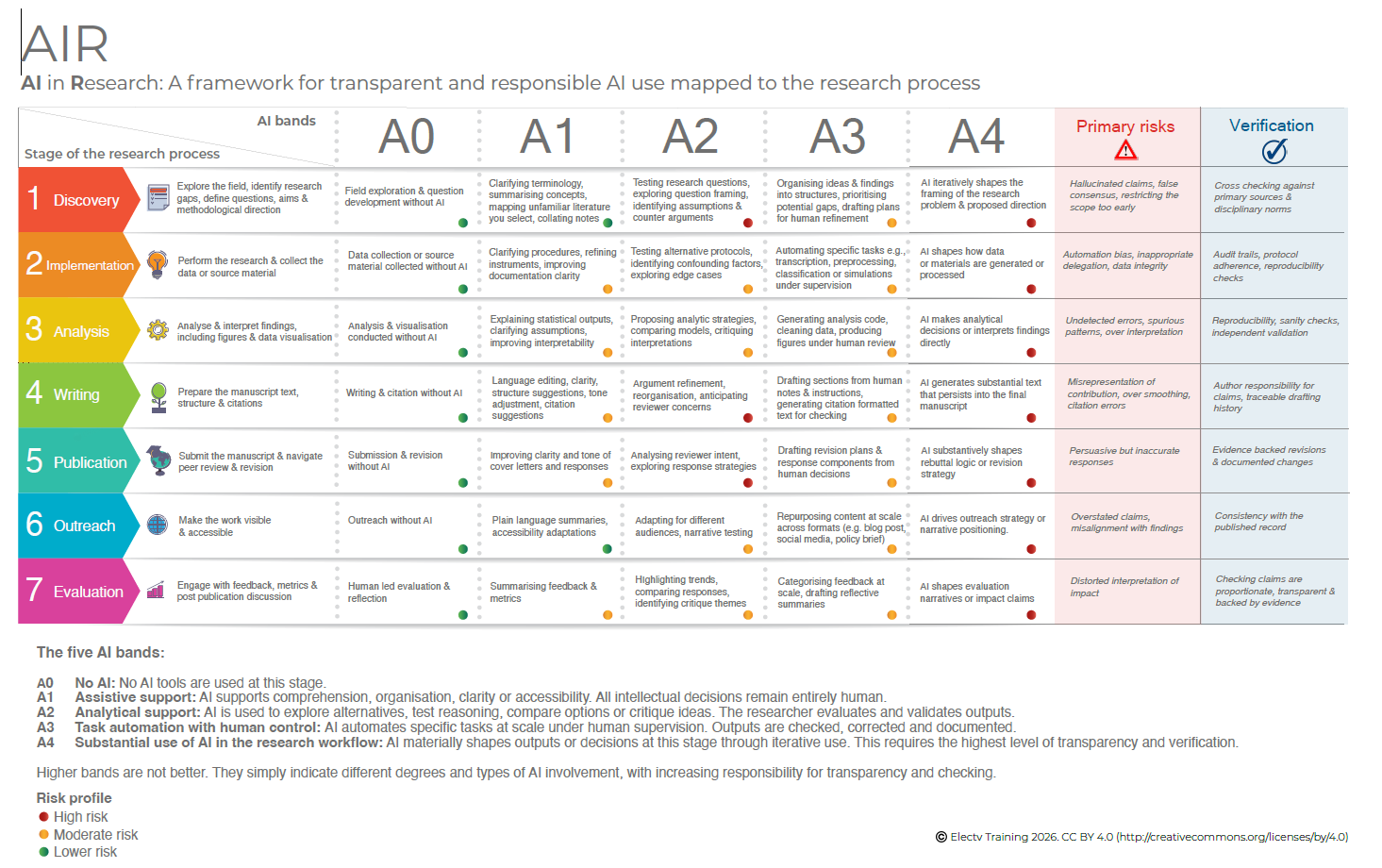
Marco AIR para uso responsable de IA: útil pero revelador de nuestras inconsistencias
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
Creo que es muy útil para resolver algunas de las dudas que surgen en mis charlas sobre IA generativa en Research.
Con esta tabla, en menos de 5 minutos, puedes informar con transparencia sobre el uso que has hecho de la IA y las verificaciones que has realizado (la última columna) para estar seguro de que lo etiquetado como riesgo moderado no representa ningún “concern” para la validez de tu trabajo.
Intentar justificar que lo etiquetado como riesgo elevado no te afecta podría dar lugar a un artículo por cada una de las casillas de la columna A4.
Y este es el talón de Aquiles de todo esto… si alguien te obliga a demostrar punto por punto que estás exento de riesgos y sesgos, igual necesitas uno o dos años de trabajo para justificar adecuadamente cualquier artículo… incluso los que has escrito completamente “a mano” sin ayuda de ninguna IA generativa.
Es un poco sorprendente el doble rasero que se aplica, no pidiendo ninguna justificación si lo haces tú solito (proyectando todas tus torpezas y sesgos implícitos), y abrumándote con justificaciones si te apoyas en IA generativa. No, si no está prohibido que la uses, pero si dices que la usas, debes invertir una burrada de horas de trabajo para justificar “adecuadamente” que el uso ha sido correcto.
¿Alguien me ha preguntado alguna vez si he usado correctamente SPSS en los artículos que he escrito en los últimos 30 años? ¡Pero si, las veces que intento adjuntar la sintaxis, los revisores me dicen que quite esa información porque les “despista” y hace innecesariamente largo el artículo!
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
Voy a compartir mi reflexión personal del proceso, si me ha servido para algo y las sensaciones que me han ido provocando las diferentes decisiones que he ido tomando.
Empecemos por algunos hechos:
Tengo mucha producción. Me refiero a que tengo más de 7 posibles aportaciones (5 principales más dos sustitutorias). Eso es una ventaja porque me permite elegir. Es, al mismo tiempo, un fastidio porque me obliga a perder el tiempo tomando las decisiones sobre qué descartar. Decisiones que no son sencillas porque, al menos, hay 13 o 14 artículos con claro potencial. Luego hay varios artículos más que claramente no iban a ser candidatos -porque son protocolos y para mí confluyen con una de las aportaciones principales, o son de áreas ajenas al management o siempre fueron “artículos menores” que me interesaba escribir para dar cauce a una idea o para forzarme a aprender algo con rigor-.
Algunas de las circunstancias reductoras de puntuación afectan directamente a varios de mis trabajos.
Y pasemos ahora a mis inferencias, opiniones y percepciones. Para mí, estos son los “takeaways” que me llevo del proceso de reflexión, siendo consciente de que son solo el modo en que veo el asunto y, sin duda, están sesgados.
Algunos de los que yo considero mis mejores trabajos por lo que ha supuesto escribirlos, la contribución que yo creo que tienen en la academia y en la sociedad y que, además, han sido de los más citados (no me creo que las citas indiquen nada, pero supongo que para mucha gente este es un indicador imprescindible), no los puedo poner como meritos porque sería un suicido (directamente me van a poner un cero porque cumplen alguno o varios de los criterios de minoración de puntuaciones). Por ejemplo:
Marin-Garcia, J. A., Vidal-Carreras, P. I., & Garcia-Sabater, J. J. (2021). The Role of Value Stream Mapping in Healthcare Services: A Scoping Review. International Journal of Environmental Research and Public Health, 18(3), 951. https://doi.org/10.3390/ijerph18030951
No me apetece jugármela a tener que defender mis méritos en una reclamación, de modo que voy a ser cauto y conservador y elegir como méritos los que creo que van a gustar al panel, no los que yo creo que realmente son mis mejores trabajos. Me he permitido la licencia de ser “irreductible” en una de las sustitutorias, donde he puesto una aportación de investigación sobre aprendizaje. Porque desde el primer sexenio me impuse el compromiso de poner siempre al menos una investigación docente en mis aportaciones:
Aznar-Mas, L. E., Atarés Huerta, L., & Marin-Garcia, J. A. (2021). Students have their say: Factors involved in students’ perception on their engineering degree. European Journal of Engineering Education, 46(6), 1007–1025. https://doi.org/10.1080/03043797.2021.1977244).
De las 5 aportaciones principales, yo solo habría mantenido una o dos de ellas (y también habría puesto otra en lugar de una de las sustitutorias). ¿Por qué no lo he hecho? Porque me “he cagado”. Tengo la seguridad de que no lo iban a entender en la comisión y que peligraba el sexenio… que no pasa nada, ya tengo 3 sexenios, y un sexenio son solo 140 euros al mes de extra en la nómina. Es triste, pero me he vendido por 140 euros de mierda (que, además, no me hacen falta para llegar a final de mes, esa enorme suerte tengo).
¿Cuales hubiera puesto yo de no haberme “cagado”? Sin duda, habría puesto al menos dos contribuciones sobre las cosas que hicimos durante la época de COVID, en la que nos volcamos a dedicar horas y todos nuestros conocimientos para apoyar a los hospitales. A los que nos quisieron como colaboradores, y hasta que nos obligaron a dejar de colaborar con ellos desde las altas esferas (bueno, nunca les hicimos caso y seguimos desde la clandestinidad 😉 ). Gracias a ello, recibimos el premio “Luis Merelo y Más” del Colegio de Ingenieros Industriales de la Comunidad Valenciana. Muchas de las cosas que aprendimos entonces también las pudimos aplicar durante la catástrofe de la Dana del 2024. Como representativo de esta línea hubiera elegido estos dos trabajos:
Marin-Garcia, J. A., Garcia-Sabater, J. J. P., Ruiz, A., Maheut, J., & Garcia-Sabater, J. J. P. (2020). Operations Management at the service of health care management: Example of a proposal for action research to plan and schedule health resources in scenarios derived from the COVID-19 outbreak. Journal of Industrial Engineering and Management, 13(2), 213. https://doi.org/10.3926/jiem.3190
Redondo, E., Nicoletta, V., Bélanger, V., Garcia-Sabater, J. P., Landa, P., Maheut, J., Marin-Garcia, J. A., & Ruiz, A. (2023). A simulation model for predicting hospital occupancy for Covid-19 using archetype analysis. Healthcare Analytics, 3, 100197. https://doi.org/10.1016/j.health.2023.100197
Además, habría puesto mis artículos sobre guías para la difusión de la ciencia. Sinceramente creo que son de las cosas más útiles e interesantes que he hecho (aunque sea yo el único que piense eso):
Marin-Garcia, J. A. (2021). Three-stage publishing to support evidence-based management practice. WPOM-Working Papers on Operations Management, 12(2), 56–95. https://doi.org/10.4995/wpom.11755
Marin-Garcia, J. A., & Alfalla-Luque, R. (2021). Teaching experiences based on action research: A guide to publishing in scientific journals. WPOM-Working Papers on Operations Management, 12(1), 42–50. https://doi.org/10.4995/wpom.7243
Marin-Garcia, J. A., Garcia-Sabater, J. P., & Maheut, J. (2022). Case report papers guidelines: Recommendations for the reporting of case studies or action research in Business Management. WPOM-Working Papers on Operations Management, 13(2), 108–137. https://doi.org/10.4995/wpom.16244
Sobre investigación docente habría elegido este, porque realmente es el trabajo que más transforma el aprendizaje de 60 futuros directivos-as cada año:
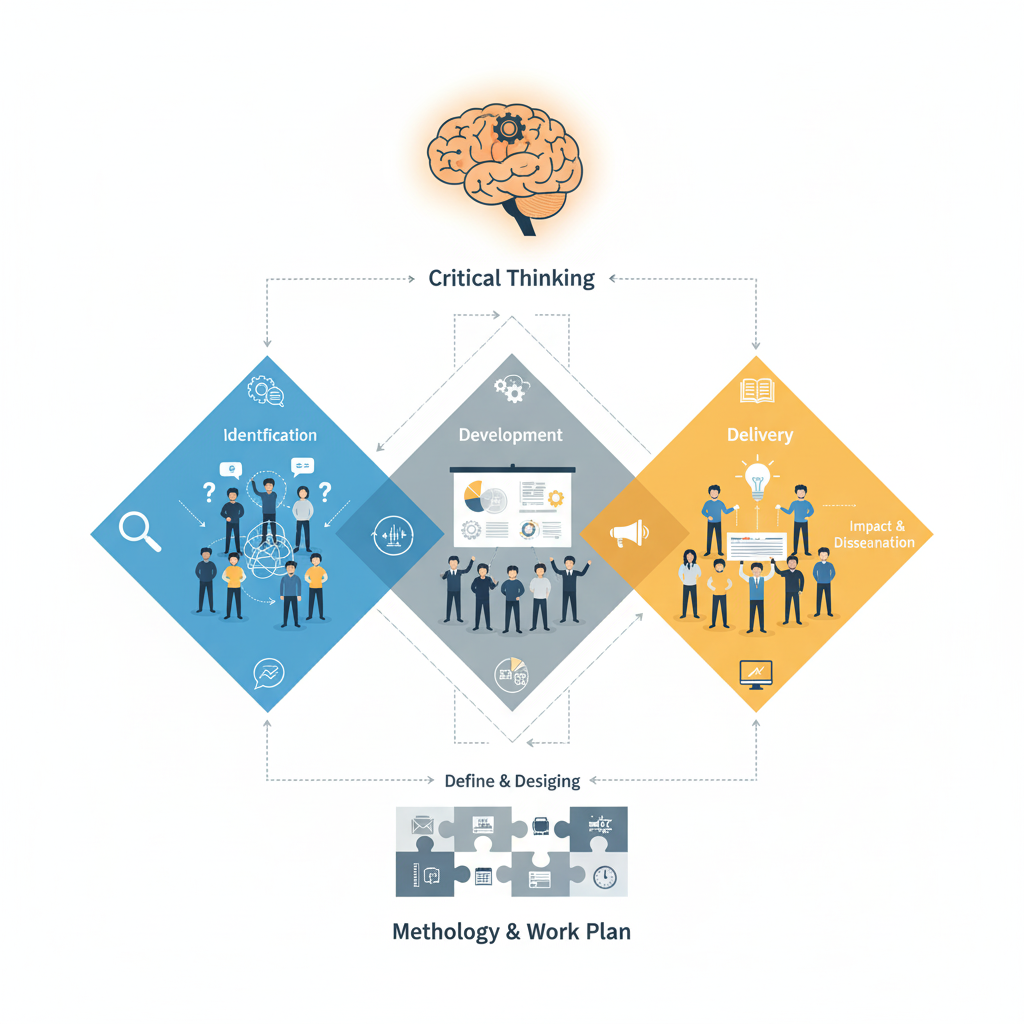
Marin-Garcia, J. A., Garcia-Sabater, J. J., Garcia-Sabater, J. P., & Maheut, J. (2020). Protocol: Triple Diamond method for problem solving and design thinking. Rubric validation. WPOM-Working Papers on Operations Management, 11(2), 49–68. https://doi.org/10.4995/wpom.v11i2.14776
También habría incluido alguna aportación representativa de mi línea de investigación en Gestión de Recursos Humanos. Mi solicitud ha quedado demasiado sesgada hacia la Dirección de Operaciones. Por ejemplo habría incluido:
Marin-Garcia, J. A., Bonavia, T., & Losilla, J. M. (2020). Changes in the Association between European Workers’ Employment Conditions and Employee Well-being in 2005, 2010 and 2015. Int J Environ Res Public Health, 17(3), 1048. https://doi.org/10.3390/ijerph17031048
Resumiendo, no me he atrevido a dejarme llevar por la interpretación que yo hago de cuál creo que es el espíritu de la norma. He preferido autocensurarme y hacer una solicitud estándar, del montón, doblegando mi espíritu crítico, mi creatividad, y mi compromiso con una pasión para encajar en el estrecho corsé de lo que creo (sin ninguna certeza) que se puntúa en mi campo científico. Esto me deja una profunda desazón y vergüenza. No ha sido una experiencia agradable el tener que pasar por esto. Y me deja preocupado. Si algo que no necesito es capaz de pervertir mi comportamiento, y hacer que me venda y me aleje de mis creencias solo por conseguir una métrica, estamos realmente “jodidos” en la academia.
Si no tuviera la seguridad de que me van a sobrar aportaciones y que, por lo tanto, puedo dedicarme a investigar lo que creo, en conciencia, que es lo que debo investigar, habría tenido una enorme presión por dejar de hacer las cosas en las que creo, para dedicar mi escaso tiempo solo a las cosas que me van a puntuar. Por suerte, yo abordo todo lo que hago como un proyecto de publicación de artículos, lo que me genera un volumen alto de opciones y permite que, cosas que sé desde el principio que jamás serán puntuables, puedan tener su oportunidad de existir y ser encontradas por potenciales lectores.
Mientras escribo esta entrada, me ha llegado al mi bandeja de entrada este anuncio de publicación de artículo:
Baruch, Y., & Budhwar, P. (n.d.). Impact and management studies: Why making practical impact is not a core academic expectation. European Management Review. https://doi.org/10.1111/emre.70051
Ha sido providencial porque aborda muchas de las cosas que yo he estado pensando estas dos últimas semanas. Os dejo algunos apuntes a modo de trailer:
El artículo alerta sobre la creciente presión gubernamental para que la investigación demuestre un impacto práctico inmediato, lo que está erosionando la función fundamental de las universidades. Esta exigencia representa una ruptura con el modelo de universidad basado en la autonomía para la búsqueda libre del conocimiento.
El problema es tanto conceptual como metodológico. Por un lado, la naturaleza misma del trabajo académico en ciencias sociales genera impacto de forma indirecta y diferida: los académicos transforman la sociedad a través de sus estudiantes y del conocimiento que estos llevan al mundo profesional, un proceso cuyo valor se manifiesta a largo plazo. Por otro lado, la medición del impacto carece de criterios válidos y fiables, siendo prácticamente imposible establecer una relación causal directa entre una investigación específica y cambios sociales u organizacionales concretos.
Los autores no rechazan el valor del impacto práctico, sino su imposición como criterio central de evaluación académica. La creación de conocimiento, el rigor intelectual y la libertad académica deben constituir el “imperativo” de la universidad, mientras que la aplicación práctica inmediata puede ser un resultado deseable pero no una obligación. Invertir esta prioridad, convirtiendo el impacto como motor principal de la actividad académica, supone desviar recursos intelectuales de la generación de conocimiento original hacia la demostración de utilidad inmediata, comprometiendo así la esencia misma de la institución universitaria.
Este año me toca presentar la solicitud para el sexenio de investigación. La experiencia de las tres veces anteriores fue frustrante, no por el resultado (conseguí el informe favorable directo en las tres ocasiones), sino por la sensación de pérdida de tiempo en una actividad que no añadía absolutamente nada de valor (ni a mí ni a la sociedad).
Ahora voy a intentar que sea diferente; no sé si lo conseguiré, porque los sistemas pensados para “certificar” la calidad, y no para “promover” la calidad, no ayudan demasiado y tienen una pasmosa capacidad para convertir las tareas en “No Valor Añadido, No Evitable”.
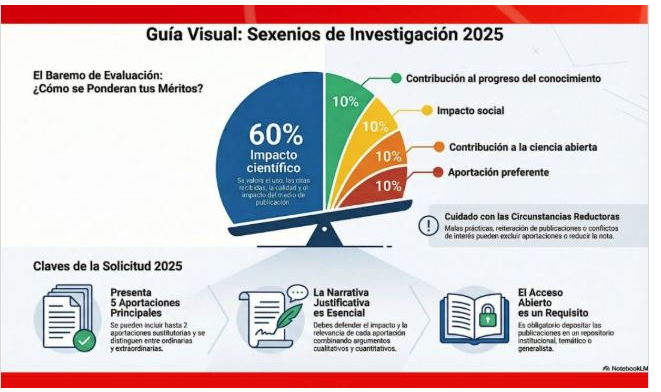
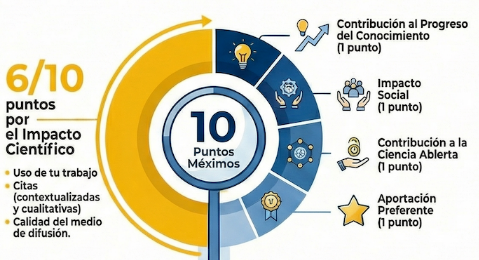
¿Qué es lo que me planteo? Aprovechar que voy a hacer una mirada retrospectiva a mis publicaciones y reflexionar sobre el impacto social, la contribución al progreso del conocimiento y el impacto científico para decidir qué cosas tengo que cambiar en el futuro.
El principal problema que anticipo es que los indicadores que tendré disponibles no me darán ninguna información relevante para tomar decisiones.
Por ejemplo, aunque se me hubiera ocurrido etiquetar con la TAG #sexeniosjamgupv2025 todas las entradas que he hecho en las diferentes redes sociales, ¿para qué me sirve ver el número de “likes” en linkedin, Facebook, X o Bluesky? ¿Realmente me dice algo sobre cómo mejorar el tipo de investigación que hago?
Supongo que podría decir algo parecido de las citas, ¿que no me citen (o que me citen) significa que realmente no (si) se han leído mi trabajo?
Y si no me sirven los indicadores disponibles, ¿cómo puedo tomar decisiones basadas en evidencia y no usar autoengaños para justificarme ante mí mismo?
Pues este tipo de cosas son las que quiero darles algunas vueltas las próximas semanas. Si no aclaro nada, esta edición de la solicitud de sexenios habrá sido, una vez más, una pérdida de tiempo. Si saco alguna conclusión, tendré que agradecer a ANECA por obligarme a invertir mi tiempo en preparar una solicitud que ha desencadenado un proceso beneficioso.
Mi opinión en estos momentos, basada en los experimentos que llevo haciendo desde hace un par de años (experimentos informales, no del todo sistemáticos, y sobre todo centrados en los temas o asuntos que me interesan a mí en mi día a día como investigador, docente y consultor), es que no hay nada en nuestro campo que aporte resultados “decentes” (que sean útiles, ciertos o que no tengan un sesgo tremendo en la respuesta).
Tanto OpenEvidence como Consensus, Elicit y similares solo aciertan (cuando aciertan) con literatura de ciencias de la salud.
Los motivos son claros para mí. Primero el modo que esas comunidades difunden su ciencia:
El tipo de artículos e investigaciones que hacen
Lo específicos que son al emplear términos y la estricta nomenclatura que usan (nunca emplean el término “dolor de cabeza”, usan, por ejemplo, cefalea tensional, neuralgia o migraña…, y cada uno es diferente de los otros)
El consenso en la reutilización de instrumentos de medida que se han demostrado válidos y fiables
y la tradición en “medicina basada en evidencia” que tienen (que igual es el origen de todo lo anterior)
Eso les permite que la IA pueda sacar resultados interesantes.
Además, aunque ya más tangencialmente, el conjunto de documentos con el que se ha entrenado el modelo (que claramente está sesgado a esas ciencias, porque entiendo que es donde más negocio pueden hacer los que venden esas plataformas).
Sin embargo, en el caótico mundo de la investigación en Management, donde cada uno pone el nombre que le da la gana a las “cosas” y midiéndolo cada vez de una forma distinta, el resultado es que una misma palabra significa cosas distintas en distintos artículos (homonimia) y, al mismo tiempo, las mismas cosas se nombran con palabras completamente diferentes (sinonimia).
No sé si resolviendo esto resolveríamos completamente el problema, pero habríamos dado un paso de gigantes para poder hacer una extracción sistemática a gran escala del enorme conocimiento que se ha ido generando en el área y que, de momento, está enmarañado.
Extended Title: Action research on designing materials, protocol, and feasibility of a complex intervention to foster critical thinking and apply the triple diamond framework in group decision-making.
This project aims to enhance students’ critical thinking and decision-making skills by developing, testing, and refining a structured group decision-making framework called the triple diamond. It focuses on identifying misconceptions that hinder students’ use of this framework and improving pedagogical interventions through active, collaborative learning and evidence-based methodologies.
Project scope and participants: The innovation will be implemented across multiple courses in engineering, logistics, and business master’s programs, involving diverse student groups facing recurring difficulties in applying structured decision-making methods.
Problem identification: Students consistently rely on intuitive rather than structured approaches in group decisions, struggling to apply the triple diamond framework despite repeated instruction and practice. This issue is persistent and mirrors challenges observed in professional settings.
Theoretical foundations: The project integrates concepts of misconceptions, knowledge elicitation, threshold concepts, and decoding the discipline to reveal and address barriers to expert-like thinking in decision processes. It emphasizes the reorganization of knowledge fragments rather than the mere replacement of incorrect ideas.
Learning objectives: Students will learn to manage group decision processes using the triple diamond, define tasks and prioritization criteria explicitly, analyze innovation competencies, and develop reasoned, evidence-based reports, all enhancing critical thinking skills.
Methodology: The project employs active and collaborative learning through structured three-hour classroom dynamics complemented by autonomous preparatory work. It incorporates innovative visual case representations, reflective learning journals, and think-aloud protocols to elicit student thinking and identify misconceptions.
Expected outcomes: These include identifying common misconceptions, adapting and developing rubrics for assessment, quantifying students’ valuation of innovation competencies, improving decision quality and reducing cognitive biases, and evaluating the impact of different case presentation formats on engagement and critical thinking.
Work plan and tools: The two-year plan details tasks such as material development, rubric adaptation, protocol design, experimental validation, and dissemination through academic articles and conferences. Project management uses O365 tools with regular team meetings and quality control processes.
Evaluation strategy: Evaluation includes measuring the number and categorization of misconceptions, rubric validation, analysis of student preferences and clusters, transferability assessments, pre-post intervention comparisons, and engagement metrics using established models. Data collection involves think-aloud sessions, forum analyses, and observations.
Impact and dissemination: The project aims to improve teaching and learning by making decision-making processes transparent and evidence-based, enabling transfer across disciplines and formats, including MOOCs. Results will be shared via conferences, indexed publications, online platforms, and social media, ensuring broad accessibility and adoption.
Esta es mi conclusión, contraría a la de las personas que han escrito este artículo. Para mí, 0.4 puntos de diferencia en una escala de 1 a 7 sobre algo complicado de medir y con mucha subjetividad, me parece que es más bien lo contrario, un nivel de acuerdo excepcional. Tsirkas, K., Chytiri, A. P., & Bouranta, N. (2020). The gap in soft skills perceptions: A dyadic analysis. Education and Training, 62(4), 357–377. https://doi.org/10.1108/ET-03-2019-0060
Luego hay un “temita” que normalmente me desespera un poco y es el de los gráficos falsos (si, vale no son falsos, pero están trucados). Este radar chart es un ejemplo clarísimo. El truco es que no pones el principio y el final de los ejes del gráfico en el nivel mínimo y máximo de la escala respectivamente (que sería un 1 y un 7). Sino que el centro lo pones en un valor arbitrario, por ejemplo, el 4, y el tope de la escala lo pones en 6,5 (otro valor arbitrario). De modo que cada “curva de nivel” ya no representa un punto sino, quizás, 0,2 puntos y entonces las diferencias visuales quedan magnificadas. Por supuesto, si no pones los números el impacto es mayor. Aunque los pongas, el truco sigue funcionando porque el espacio visual impacta más que el hacer una resta entre 5.76 y 5.29 (por ejemplo, para trabajo en equipo). Si queréis engañar o confundir a la audiencia es la mejor forma de hacerlo, pocas personas se darán cuenta del truco y el impacto es ¡Wohw, vaya diferencia más brutal!
Para ir avanzando en mi modelo de “second brain”, estaba reflexionando sobre el procesos que sigo para extraer la información y he tenido que hacer un alto para aclarar términos.
La literatura (ver referencias) suele identificar diferente cantidad de etapas en el proceso de análisis de contenido, y darle nombres distintos a etapas que tienen muchas cosas en común. Por eso he dedicado toda la mañana a integrar la información en una tabla en la que lo relevante es la definición basada en tareas. Que haya estado más o menos acertado al capturar los significados o al agrupar los sinónimos, creo que es mucho menos relevante.
Term used*
Definition (qué se hace)
Chunk (free coding; open coding; free text; annotation; quotation)
Extraer fragmentos de información; seleccionar la “quotation/annotation” sin añadir ningún “code” es el equivalente a resaltar o subrayar un fragmento de texto (“chunk” en el lenguaje de IAgen). Representan la voz de la persona informante sin interpretación del investigador-a
Open Coding (1st-order concept, initial coding)
Selección y refinamiento de los códigos para que representen los temas principales de los chunks, sus similitudes y diferencias. Interpretación conceptual de los open coding y decidir cómo agruparlos bajo temas más abstractos. Emergen nuevos conceptos que ayuden a describir, entender los chunks, o a rellenar gaps entre chunks
Focused coding (axial coding, 2nd order themes)
Crear una jerarquía o relación entre los focused codes, añadiendo categorías, y creando una integración conceptual a través de las relaciones entre temas y/o conceptos que explica el cómo, el porqué o las causas (que viene siendo una representación gráfica de la teoría)
Crear una jerarquía o relación entre los focused codes, añadiendo categorías, y creando una integración conceptual a través de las relaciones entre temas y/o conceptos que explica el cómo, el por qué o las causas (que viene siendo una representación gráfica de la teoria)
* Incluyo entre paréntesis sinónimos utilizados por diferentes tradiciones
Marin-Garcia, J. A., Martinez-Tomas, J., Juarez-Tarraga, A., & Santandreu-Mascarell, C. (2024). Protocol paper: From Chaos to Order. Augmenting Manual Article Screening with Sentence Transformers in Management Systematic Reviews. WPOM-Working Papers on Operations Management, 15, 172–208. https://doi.org/10.4995/wpom.22282
What is it about?
This protocol paper describes a new method to help researchers screen and classify scientific articles more efficiently during systematic literature reviews. The authors propose using AI language models called “sentence transformers” to automatically analyze article titles and abstracts, comparing them to the review’s topic of interest. This helps researchers prioritize which articles to review first, rather than working through them randomly. The method was tested with 14 different AI models on a small set of articles about workplace management practices.
As scientific publications grow exponentially, researchers struggle to efficiently review all relevant literature. This method could: * Save significant time in the screening process * Reduce researcher fatigue and potential bias * Make systematic reviews more accessible to researchers with limited resources * Help democratize access to advanced AI tools for academic research * Support evidence-based management practices by making literature reviews more feasible The approach is particularly valuable because it’s designed to complement rather than replace human judgment, and can be implemented using free, accessible tools.
Perspectives
“
This protocol represents an innovative bridge between cutting-edge AI technology and traditional academic research methods. The authors’ commitment to making the tool freely available and easy to use for researchers worldwide, regardless of technical expertise or resources, is particularly noteworthy. The pilot results suggest promising potential, though more testing is needed to validate the approach at larger scales.
This page is a summary of: Protocol paper: From Chaos to Order. Augmenting Manual Article Screening with Sentence Transformers in Management Systematic Reviews, WPOM – Working Papers on Operations Management, December 2024, Universitat Politecnica de Valencia, DOI: 10.4995/wpom.22282.