Esta semana lo he probado yo mismo aplicado al Grado de Ingeniería de Organización Industrial. El jueves voy a ponerlo en práctica con unos 35 asistentes al taller y veremos qué pasa. Hasta ahora solo lo he aplicado a mis propias asignaturas, que no es exactamente una muestra imparcial.
European Commission. Directorate General for Employment, Social Affairs and Inclusion. (2019). ESCO handbook: European skills, competences, qualifications and occupations. Publications Office. atlasTI-ART-639 soft Skills. https://data.europa.eu/doi/10.2767/934956
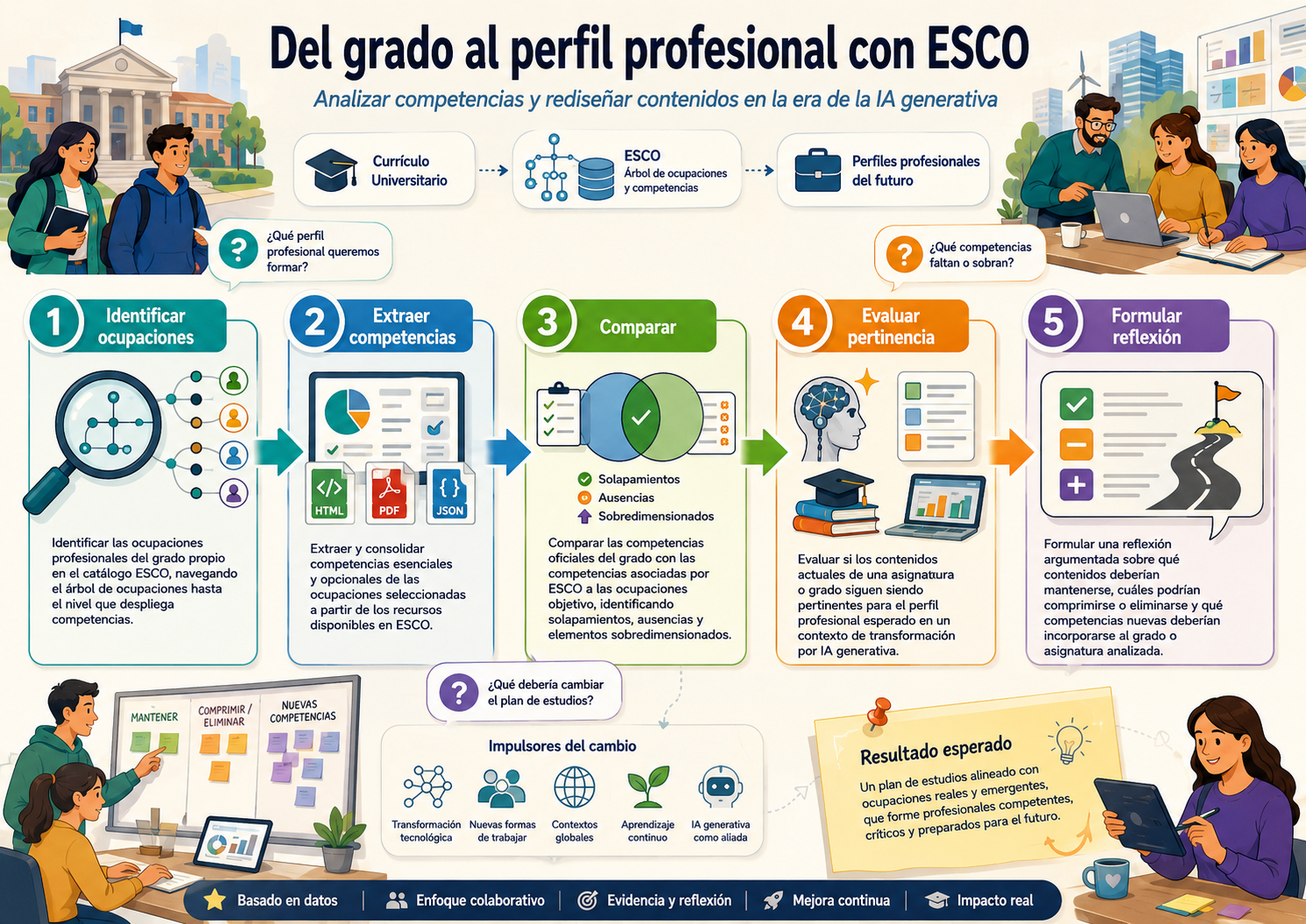
RESULTADOS–> [en construcción]
Esa metodología me permitirá activar un proyecto atascado sobre soft-skills
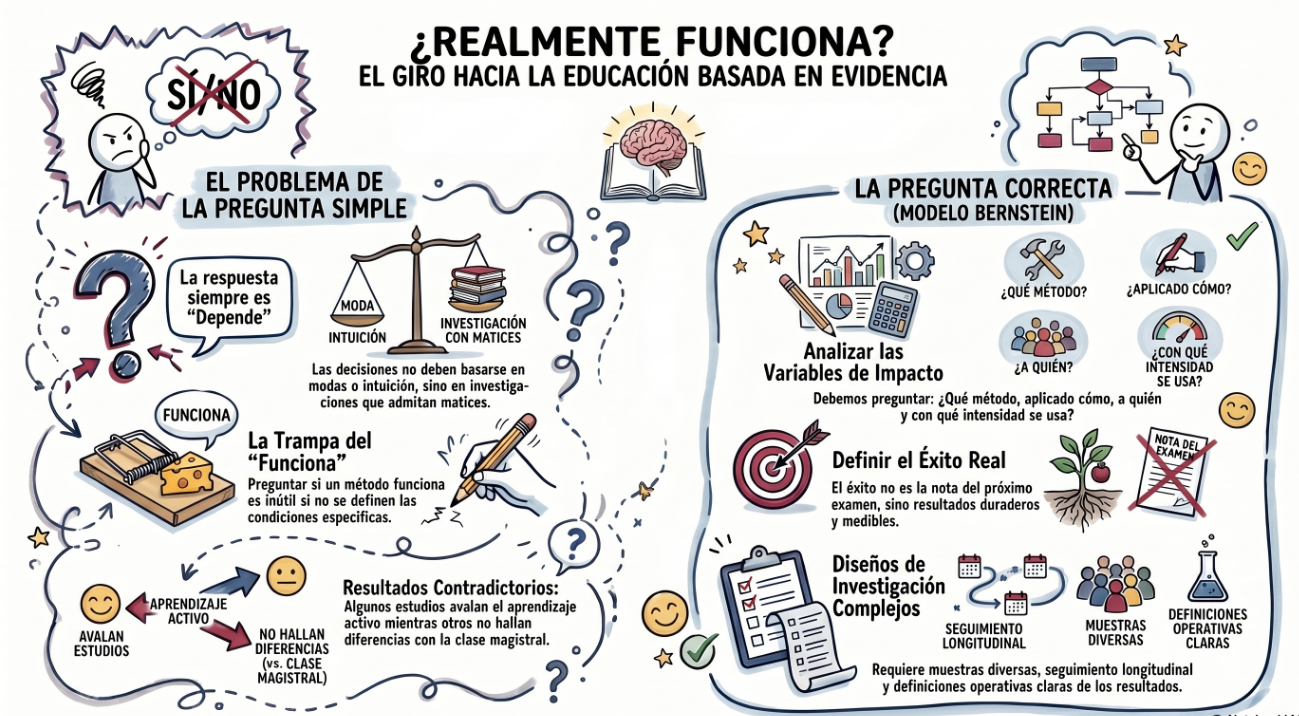
¿Qué es evidence-based?, dices mientras clavas en mi pupila tu pupila azul. Voy a aprovechar el resumen de un artículo de investigación en educación superior para dar una respuesta que sirva tanto para management en general, como para recursos humanos, como para dirección de operaciones, o para educación superior. Para cualquier campo donde alguien quiera tomar decisiones apoyándose en investigación en lugar de en intuición o moda.
Bernstein, D. A. (2018). Does active learning work? A good question, but not the right one. Scholarship of Teaching and Learning in Psychology, 4(4), 290–307. http://dx.doi.org/10.1037/stl0000124
En los años 50 el debate era “¿funciona la terapia?”, y la pregunta resultó ser inútil, porque la única respuesta posible es “depende”. Con el aprendizaje activo estamos en el mismo sitio: hay estudios que dicen que sí, otros que dicen que más o menos, y otros que no encuentran diferencias con la clase magistral. Bernstein propone que dejemos de preguntarnos si “funciona” y empecemos a preguntar : ¿qué tipo de aprendizaje activo, aplicado cómo, a quién, con qué nivel de intensidad y adherencia, produce qué tipo de resultados y durante cuánto tiempo?
El problema es que responder a ese tipo de preguntas es bastante difícil. Requiere diseños más complejos, muestras diferentes, seguimiento longitudinal, y una definición operativa de “funciona” que no sea la nota del examen de la semana siguiente. No es lo que la mayoría de los papers de docencia hacen (ni los de management).
Pero ese es precisamente el trabajo que debemos hacer: el que responde preguntas que importan de verdad.
Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
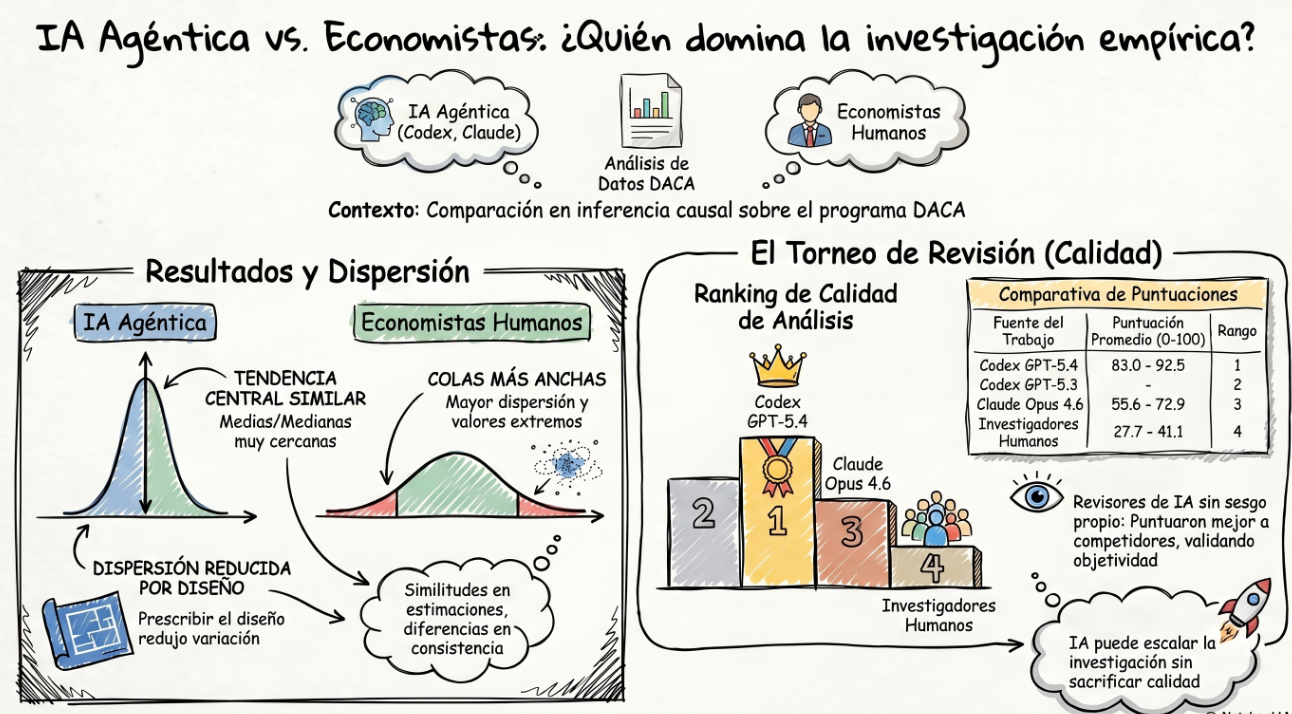
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
Humanos no ponderados: mínimo −4,9 y máximo 66,0.
Humanos ponderados: mínimo −4,9 y máximo 66,0.
GPT-5.4: mínimo 1,4 y máximo 7,0.
GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.
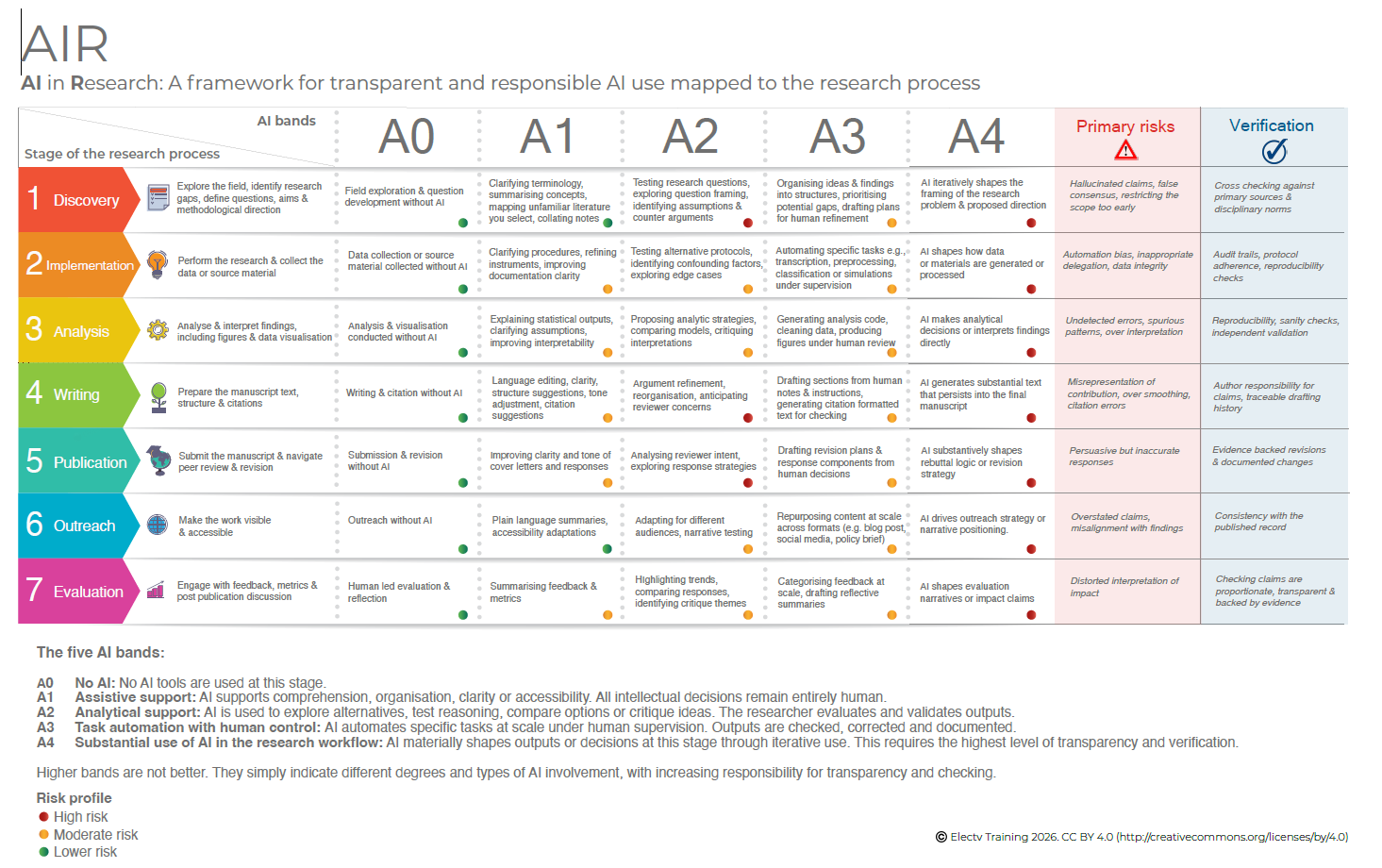
Marco AIR para uso responsable de IA: útil pero revelador de nuestras inconsistencias
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
Creo que es muy útil para resolver algunas de las dudas que surgen en mis charlas sobre IA generativa en Research.
Con esta tabla, en menos de 5 minutos, puedes informar con transparencia sobre el uso que has hecho de la IA y las verificaciones que has realizado (la última columna) para estar seguro de que lo etiquetado como riesgo moderado no representa ningún “concern” para la validez de tu trabajo.
Intentar justificar que lo etiquetado como riesgo elevado no te afecta podría dar lugar a un artículo por cada una de las casillas de la columna A4.
Y este es el talón de Aquiles de todo esto… si alguien te obliga a demostrar punto por punto que estás exento de riesgos y sesgos, igual necesitas uno o dos años de trabajo para justificar adecuadamente cualquier artículo… incluso los que has escrito completamente “a mano” sin ayuda de ninguna IA generativa.
Es un poco sorprendente el doble rasero que se aplica, no pidiendo ninguna justificación si lo haces tú solito (proyectando todas tus torpezas y sesgos implícitos), y abrumándote con justificaciones si te apoyas en IA generativa. No, si no está prohibido que la uses, pero si dices que la usas, debes invertir una burrada de horas de trabajo para justificar “adecuadamente” que el uso ha sido correcto.
¿Alguien me ha preguntado alguna vez si he usado correctamente SPSS en los artículos que he escrito en los últimos 30 años? ¡Pero si, las veces que intento adjuntar la sintaxis, los revisores me dicen que quite esa información porque les “despista” y hace innecesariamente largo el artículo!
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
I will be presenting this research at the upcoming XVII International Workshop ACEDEDOT – OMTECH 2026, taking place in Almería, Spain, from March 12-14, 2026:
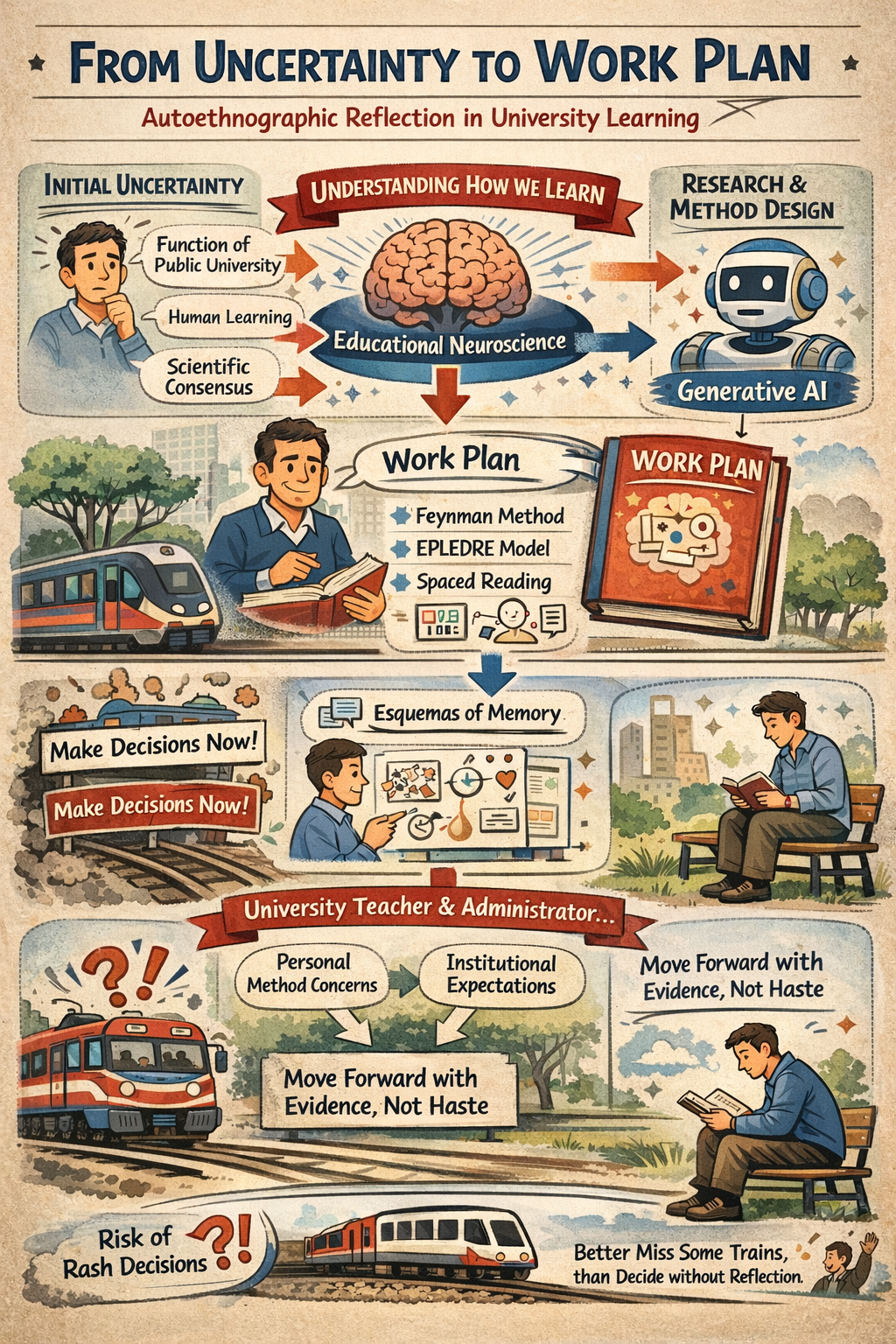
This communication presents an autoethnographic reflection. Building on four fundamental premises about the function of Spanish public universities and the established mechanisms of human learning, the author documents his personal journey from initial uncertainty to the design of a systematic work plan. The study focuses on understanding the current scientific consensus on how learning is consolidated in the brain and exploring the possibilities of generative AI to enhance this process in the university context. Drawing on the work of Héctor Ruiz Martín, a work plan is designed that combines recommendations from educational neuroscience with the Feynman method and the EPLEDRE model, including spaced reading, creation of sketchnote-type graphic schemes from memory, and public communication of the knowledge constructed. The communication shares the first graphic schemes developed and reflects on the author’s dual position as university teacher and administrator, facing both his own methodological uncertainties and institutional expectations for strategic guidance. It questions the “collective panic” surrounding the emergence of generative AI in universities and the pressure to make quick decisions without sufficient reflection. It proposes replacing reactive urgency with a deliberate process of calm, evidence-based reflection and pilot experimentation, recognizing that in contexts of accelerated change, it is preferable to miss some “trains” rather than make biased decisions under collective amygdala hijacking
(Proyecto de investigación del Vicerrectorado de Planificación, Estudios, Calidad y Acreditación de la Universitat Politècnica de València. Dirección de Area de Transformación Docente e Instituto de Ciencias de la Educación)
Mientras algunas personas debaten si prohibir o no “ChatGPT” en nuestras aulas, nuestros estudiantes ya lo usan. Porque muchas de las cosas que enseñamos, la IA ya las responde mejor y más rápido. Si no identificamos qué nos hace verdaderamente valiosos como profesorado universitario, corremos el riesgo de volvernos irrelevantes.
Planteo hacer una serie de entradas donde te contaré:
→ Entrada 1: por qué decidimos investigar esto y las preguntas que nos quitan el sueño
→ Entrada 2: qué dicen los estudiantes sobre lo que nos hace insustituibles (siete cosas que valoran y tres alertas rojas)
→ Entrada 3: qué propone el profesorado y hacia dónde vamos con este proyecto
Este proyecto no va de tecnofobia ni de tecnoeuforia. Va de preguntarnos qué deberíamos seguir haciendo, qué transformar radicalmente, y qué quizá dejar de hacer.
¿que emociones genera en ti cuando oyes “Inteligecia Artificial Generativa”? (50 profesoras-es, noviembre 2025)
Mi opinión en estos momentos, basada en los experimentos que llevo haciendo desde hace un par de años (experimentos informales, no del todo sistemáticos, y sobre todo centrados en los temas o asuntos que me interesan a mí en mi día a día como investigador, docente y consultor), es que no hay nada en nuestro campo que aporte resultados “decentes” (que sean útiles, ciertos o que no tengan un sesgo tremendo en la respuesta).
Tanto OpenEvidence como Consensus, Elicit y similares solo aciertan (cuando aciertan) con literatura de ciencias de la salud.
Los motivos son claros para mí. Primero el modo que esas comunidades difunden su ciencia:
El tipo de artículos e investigaciones que hacen
Lo específicos que son al emplear términos y la estricta nomenclatura que usan (nunca emplean el término “dolor de cabeza”, usan, por ejemplo, cefalea tensional, neuralgia o migraña…, y cada uno es diferente de los otros)
El consenso en la reutilización de instrumentos de medida que se han demostrado válidos y fiables
y la tradición en “medicina basada en evidencia” que tienen (que igual es el origen de todo lo anterior)
Eso les permite que la IA pueda sacar resultados interesantes.
Además, aunque ya más tangencialmente, el conjunto de documentos con el que se ha entrenado el modelo (que claramente está sesgado a esas ciencias, porque entiendo que es donde más negocio pueden hacer los que venden esas plataformas).
Sin embargo, en el caótico mundo de la investigación en Management, donde cada uno pone el nombre que le da la gana a las “cosas” y midiéndolo cada vez de una forma distinta, el resultado es que una misma palabra significa cosas distintas en distintos artículos (homonimia) y, al mismo tiempo, las mismas cosas se nombran con palabras completamente diferentes (sinonimia).
No sé si resolviendo esto resolveríamos completamente el problema, pero habríamos dado un paso de gigantes para poder hacer una extracción sistemática a gran escala del enorme conocimiento que se ha ido generando en el área y que, de momento, está enmarañado.
Vamos a suponer que esta frase de Simon Sinek es cierta (que creo que lo es). Mi duda es si basta que uno (o unos pocos) en la cadena no tenga 💘, para destrozar el trabajo de todos los demás, en cuyo caso, cuando los procesos son largos, complejos y atraviesan diferentes unidades que no se comunican fluido entre sí, tendríamos un sistema muy vulnerable (que me temo que va por ahí la cosa).
Por ejemplo, aplicado a mi organización; si nuestro PDI, PTGA y subcontratas no 💘 UPV, nuestros estudiantes no podrán tener una experiencia memorable de su paso por la UPV. Lo que no sabría deciros es el nivel de 💘 en cada colectivo, ni si están agrupados en procesos, o cada proceso tien un poco de todo y, por lo tanto, la experiencia no sería lo maravillosa que podría ser en ninguno.
He comparado la respuesta de Claude-sonnet-4 y las de 4 grupos de estudiantes de máster (5 personas en cada grupo) con un caso que he preparado como diagnóstico inicial para comprobar las competencias de mis estudiantes el primer día de clase.
Mis estudiantes han estado trabajando 2 horas sobre un caso de 5 páginas donde su tarea estaba descrita en un párrafo y el resto era información de contextualización.
El Prompt usado con Claude-sonnet-4 en poe.com era simplemente el párrafo de descripción de la tarea a realizar sin ningún contexto adicional (ni de nivel de estudios, ni de contexto… nada).
“resuelve este caso “”Formas parte de un proyecto que pretende alinear el uso de Inteligencia Artificial (IA) con los valores y objetivos estratégicos de la UPV, de modo que la IA ayude a construir en lugar de minar el futuro que queremos ser. Como grupo, debéis manifestar vuestro punto de vista, como estudiantes universitarios, sobre cómo percibís la IAgen, explorar los problemas o inquietudes que os genera en los diferentes usos o funciones en las que os afecta como estudiantes en la universidad y clasificarlos/filtrarlos. Para acabar proponiendo un listado de recomendaciones (o guías) de uso que sugerís para resolver las causas que originan los problemas que consideráis como principales y un plan para la implementación de esas recomendaciones.”””
Todos los grupos de estudiantes, en lugar de hacer unas guías para estudiantes, han hecho recomendaciones para la universidad o sus equipos directivos. Claude-sonnet-4 ha cometido exactamente el mismo error en la primera iteración. No obstante, su informe ha sido mucho mejor que el de cualquiera de los grupos.
Le he pedido a la IA una segunda iteración: “las recomendaciones que has dado son para la institución, no has respetado la tarea que era crear recomendaciones para los estudiantes. Por otra parte, ajusta el reporte al modelo triple diamante”. En este caso ha clavado las recomendaciones, aunque su interpretación de lo que era el “framework” de triple diamante dejaba mucho que desear, pero le hubiera puesto un 5 o un 6 de nota a ese ejercicio (los ejercicios de mis estudiantes no creo que pasen de un 2 o un 3, pero a ellos no les he dado la oportunidad de repetirlo).
Conclusión:
Cuando les pido a mis estudiantes, a PRINCIPIO de curso que resuelvan un caso y les valoro en base a los resultados de aprendizaje que esperaría que tuvieran a FINAL de curso, la IA generativa les da “mil vueltas” (o por lo menos una decena).
Lo interesante aquí es qué pasará al final del curso cuando mis estudiantes hayan superado los resultados de aprendizaje esperados. La IA generativa no mejorará su nota de 5-6 (salvo que estemos ante un nuevo modelo), entonces creo que serán mis estudiantes los que le darán mil vueltas a la IA generativa.
Hoy se me ha cruzado un artículo que he leído en diagonal, saltándome toda mi GTD-disciplina-“heiunka” del día, alimentando mi procrastinación. Pero dejando de lado que se va a hundir el indicador de Volumen y el de Secuencia de mi OEE personal, un par de párrafos me han resultado útiles.
Estos párrafos hablan de los tres elementos que generan esperanza (visión compartida de un futuro ilusionante; autoconfianza; resiliencia). Lo que he pensado yo es que la esperanza incita la acción. Si queremos transformar nuestra docencia (o cualquier otra función o proceso en una organización), necesitamos no solo pensar qué hacer (que ya es una acción), sino ponerlo en práctica superando las barreras que haya y echar mano de la resiliencia cuando las cosas no salen como esperamos (si es que no salen como esperamos). Esto es complicado cuando la cultura imperante (el discurso recurrente cada vez que nos cruzamos con alguien en un pasillo, una fotocopiadora, una mesa de cafetería…) es “desesperante” además de desesperanzada. Ya llegamos tarde, pero mejor tarde que nunca, para cambiar el chip todas aquellas personas con una visión ceniza que además se dedican a contagiarla en cada encuentro con otras personas.
Visión compartida – Creer que es posible superar las circunstancias actuales
Métodos conocidos – Saber cómo llegar a las metas con prácticas apropiadas
Motivación colectiva – Tener la fuerza para resistir las dificultades juntos
La cita que ha originado esta reflexion:
“Katina Sawyer and Judy Clair (2022) outline the myriad ways through which hope plays a role in organizations. Their research can be broadly applied to the way that hope operates not only in the workplace, but also in communities organized by nationhood. They explain that hope is made up of three parts. First, organizational members need to have a shared vision for a hopeful future, as part of everyday conversation — they must believe that it is possible to move beyond their current circumstances and achieve more desirable outcomes. Second, organizational members have to believe that they know how to get to their goals via methods and practices that they deem appropriate. Goal achievement will not be straightforward; setbacks will happen and doubt will arise. And third, the organization must embody a shared sense of motivation toward their goals. When times get tough, hopeful organizations believe that they have what it takes to weather the storm. They return to the shared vision and see the relevance of sticking together.
However, it is easy to make the point that hope can backfire. A collective belief of hope is only positive when making progress toward its promises seems realistic. But when events appear to throw things off track, there’s a similar emotional contagion, but in a negative direction — when negative emotions reign, organizations become hopeless and grow increasingly more dull and de-energized.” (Seijts et al 2025)
Referencias:
Seijts, G., Opatska, S., Rozhdestvensky, A., & Hunder, A. (2025). Holding onto the victory after the victory: Leadership lessons from the war in Ukraine for recovery and positive change. _Organizational Dynamics_, 101195. https://doi.org/10.1016/j.orgdyn.2025.101195