Te propongo que uses la iconografía para reflexionar sobre qué es para ti aprender en la universidad actual.
Iconografía: estudio, descripción y clasificación de imágenes o símbolos, analizando el significado de las representaciones visuales
Yo estaba eligiendo una imagen para ilustrar una diapositiva de una presentación y, mientras dudaba entre las tres imágenes que te muestro abajo, me he dado cuenta de que mis dudas reflejaban matices de lo que me chirriaba o me encajaba. He estado unos 15 minutos analizando los símbolos y lo que me evocan. Al final me he decantado por una de ellas. Pero lo importante es lo que me ha hecho reflexionar mientras elegía. No voy a desvelarte mi reflexión para no contaminar la tuya. Te comparto el ejercicio porque, para mí, ha resultado inspirador.
¿Qué imagen representa mejor para ti el aprendizaje en la universidad? ¿Por qué?
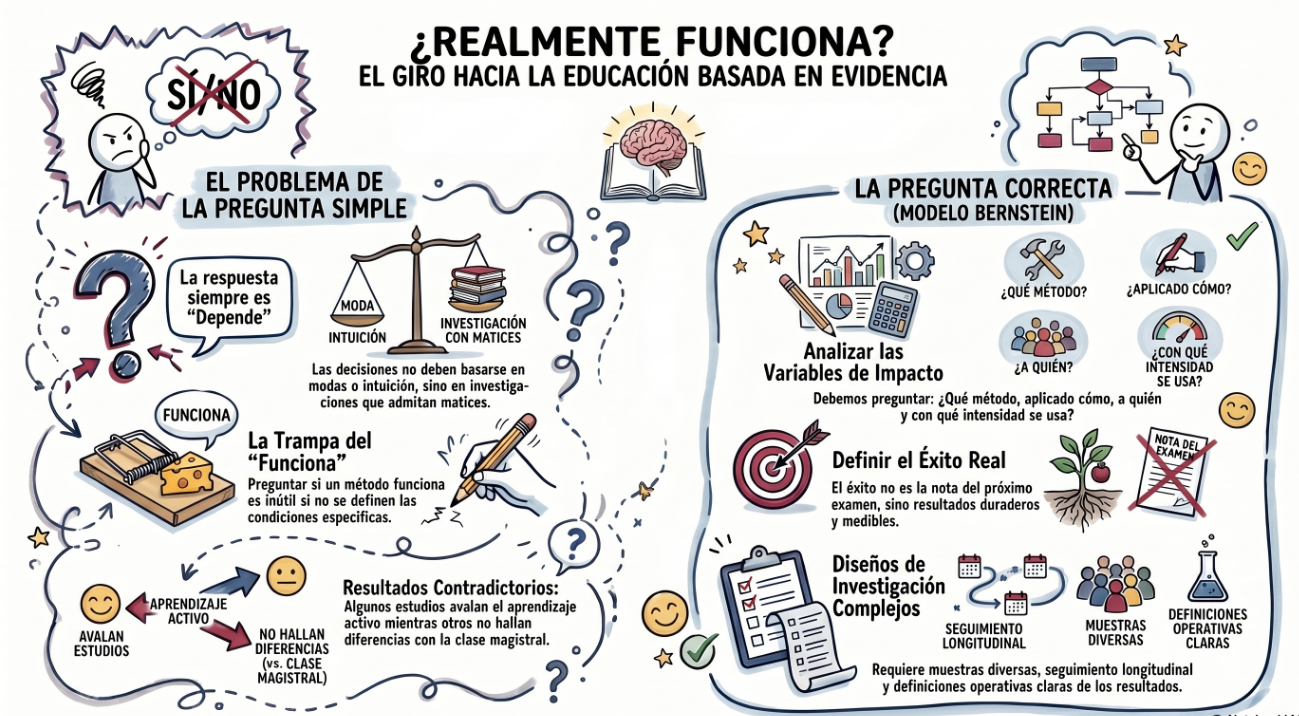
¿Qué es evidence-based?, dices mientras clavas en mi pupila tu pupila azul. Voy a aprovechar el resumen de un artículo de investigación en educación superior para dar una respuesta que sirva tanto para management en general, como para recursos humanos, como para dirección de operaciones, o para educación superior. Para cualquier campo donde alguien quiera tomar decisiones apoyándose en investigación en lugar de en intuición o moda.
Bernstein, D. A. (2018). Does active learning work? A good question, but not the right one. Scholarship of Teaching and Learning in Psychology, 4(4), 290–307. http://dx.doi.org/10.1037/stl0000124
En los años 50 el debate era “¿funciona la terapia?”, y la pregunta resultó ser inútil, porque la única respuesta posible es “depende”. Con el aprendizaje activo estamos en el mismo sitio: hay estudios que dicen que sí, otros que dicen que más o menos, y otros que no encuentran diferencias con la clase magistral. Bernstein propone que dejemos de preguntarnos si “funciona” y empecemos a preguntar : ¿qué tipo de aprendizaje activo, aplicado cómo, a quién, con qué nivel de intensidad y adherencia, produce qué tipo de resultados y durante cuánto tiempo?
El problema es que responder a ese tipo de preguntas es bastante difícil. Requiere diseños más complejos, muestras diferentes, seguimiento longitudinal, y una definición operativa de “funciona” que no sea la nota del examen de la semana siguiente. No es lo que la mayoría de los papers de docencia hacen (ni los de management).
Pero ese es precisamente el trabajo que debemos hacer: el que responde preguntas que importan de verdad.
Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
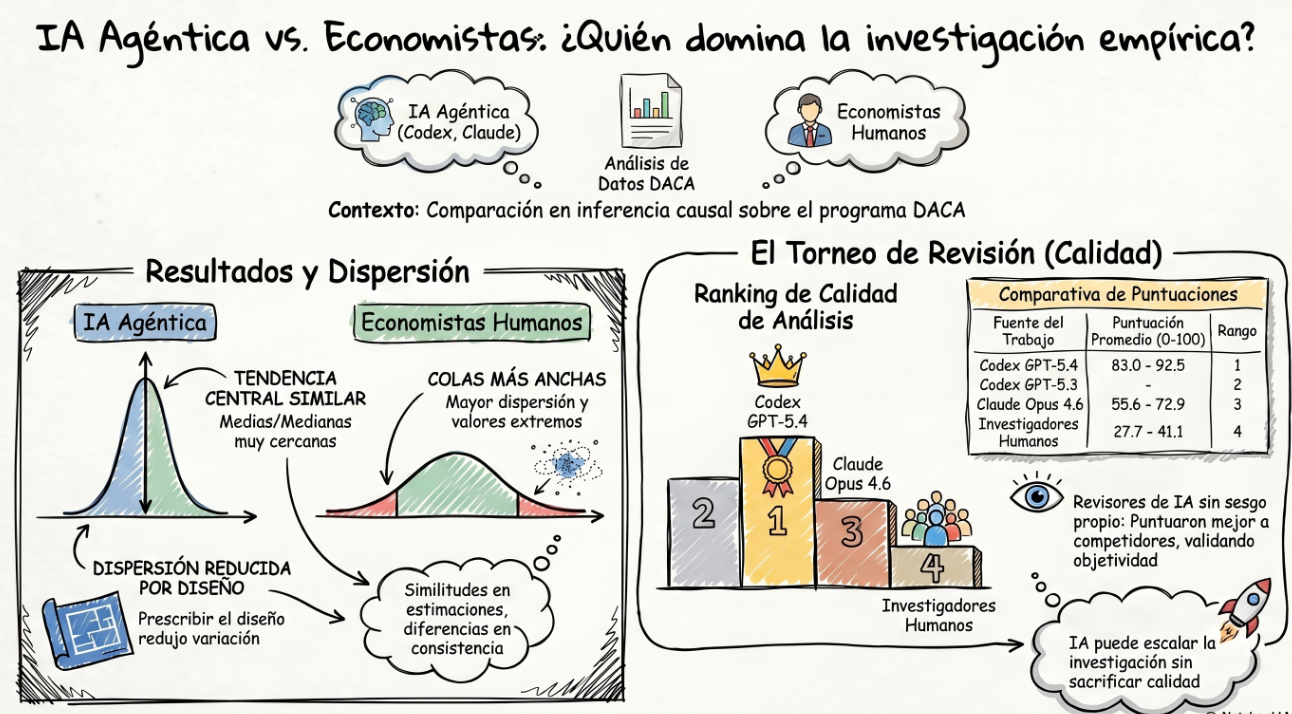
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
Humanos no ponderados: mínimo −4,9 y máximo 66,0.
Humanos ponderados: mínimo −4,9 y máximo 66,0.
GPT-5.4: mínimo 1,4 y máximo 7,0.
GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.
Estas semanas he estado expuesto a podcasts, lecturas, artículos científicos… sobre los cuatro temas que he puesto en el título de la entrada (agencia/capacidad de acción, propósito, valores y competencias). Puedes llamarlo casualidad, sincronicidad, o sesgo de confirmación: llevo tiempo pensando en algo y mi cerebro empieza a capturarlo en todas partes. Cuatro conceptos que llevan semanas rondándome y que empiezan a parecerme un sistema.
Te he de confesar que “agencia” en castellano me suena fatal. No me resulta nada intuitivo, pese a que en mis círculos cercanos se esté convirtiendo en una moda el usar esta palabra. Sin embargo, el concepto en inglés (agency) entronca con uno de los temas que ha sido foco principal en mis líneas de investigación y docencia desde hace décadas: la capacidad de actuar de forma autónoma, de ser el origen de tus propias decisiones, de no ser simplemente el resultado de las circunstancias. Tengo pendiente interiorizarlo de verdad, encontrar la manera de pensarlo en castellano sin que me rechine. Yo prefiero usar en castellano dos palabras “capacidad de acción”, no sé si algún día me acostumbraré a este calco del inglés (que no estoy seguro de que sea acertado).
Mientras iba rumiando mis paranoias contra el término “agencia”, me he tropezado con dos libros y un artículo.
Geniotipos, de Tony Struch, que va de talento. El foco del libro no son exactamente las competencias, aunque el talento tiene relación con ellas. El libro vincula talento y propósito, como si el talento sin propósito fuera un motor sin dirección.
Ikigai, de Francesc Miralles, entra directamente por el propósito, y de ahí me ha llevado a escuchar varios de sus podcasts, y de él a Alex Rovira, todos circulando alrededor de la misma pregunta: para qué estás aquí, qué tiene sentido para ti.
Hines et al (2026) rastrean la influencia que el libro Self-Help de Samuel Smiles (1859) ejerció sobre Sakichi Toyoda y, de ahí, sobre toda la cultura Toyota y el mundo Lean. El libro, de hace 165 años, habla de carácter, perseverancia, propósito de contribuir a la sociedad y desarrollo personal como responsabilidad individual.
Por último, una página web de McKinsey, “Do you know your life’s purpose?”, donde proponen que el propósito se puede mapear sobre nueve valores. Las categorías que usan no me convencen del todo, y mucho menos el modo en que las organizan. Pero me ha llamado la atención que articulan su marco de propósito en torno a “agency”.
De todo esto intuyo que los valores/talento deben orientar el propósito, que el propósito necesita del desarrollo de competencias para que no fracase el aterrizarlo. Pero es una intuición, aún estoy dándole vueltas.
Referencias:
Hines P, Liker JK, Powell DJ (2026), “The book that changed the world?”. International Journal of Lean Six Sigma, Vol. 17 No. 3, pp. 1067–1079. https://doi.org/10.1108/IJLSS-05-2026-377
McKinsey & Company (2020). Do you know your life’s purpose? https://www.mckinsey.com/capabilities/people-and-organizational-performance/our-insights/do-you-know-your-lifes-purpose
García, H., y Miralles, F. (2021). Ikigai: Los secretos de Japón para una vida larga y feliz (ed. actualizada). Urano. ISBN: 9788418714078
Estruch, T. (2022). Geniotipo: Descubre al genio que hay en ti. Diana (Grupo Planeta). ISBN: 9788418118920
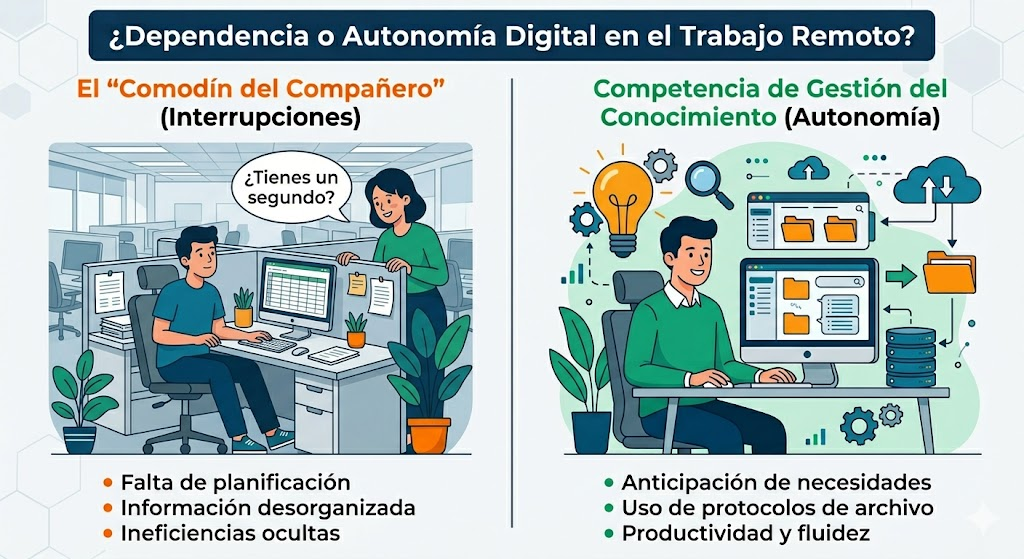
¿Cuántas veces al día (o la semana) se te acerca un compañero-a para preguntarte algo que puedes resolverle en diez segundos?
Yo he tenido que parar a pensarlo, en los primeros dos días de esta semana yo he usado el “comodín del compañero” una vez y una vez lo han usado conmigo. Igual es que cuando yo estoy en el campus, no lo están mis compañeros y al revés, y todos nos hemos acostumbrado a preguntar por whatsapp, correo, teams … y ya no interrumpimos en persona.
En remoto, es necesaria una habilidad (o competencia) que el trabajo presencial ocultaba porque nunca hizo falta desarrollarla: anticipar qué vas a necesitar y saber dónde está archivada la información/datos que necesitas antes de quedarte bloqueado.
No es un problema técnico. Es una competencia. Y probablemente no sea tan común como asumimos. En presencial, esto es/era invisible porque se puentea.
Pero puede ser el origen de ineficiencias ocultas en los equipos remotos: no falta herramienta ni conexión, falta autonomía para acceder a la información porque no se anticipa, no se planifica, no hay protocolos de archivo-recuperación-gestión del conocimiento, no se siguen los protocolos… Y esa competencia, que hasta ahora hemos dado por supuesto que todo el mundo tiene, quizás debemos empezar a diagnosticarla, ver su impacto y, si es necesario, trabajar en desarrollarla.