Me hubiera gustado hacer esta reflexión sobre una tarea de “management” (gestión), pero no he encontrado material para ello.
El trabajo que he encontrado compara sistemas de IA con humanos economistas en una tarea real de inferencia causal aplicada. La pregunta era : estimar el efecto causal de la elegibilidad para DACA sobre la probabilidad de trabajar a tiempo completo entre personas nacidas en México, residentes en Estados Unidos, usando datos de la American Community Survey.
DACA es Deferred Action for Childhood Arrivals: un programa de EE. UU. implementado en 2012 que concedía a ciertas personas inmigrantes indocumentadas que habían llegado al país siendo menores una protección temporal frente a la deportación y autorización temporal de trabajo, siempre que cumplieran varios requisitos de elegibilidad. Entre ellos, el artículo menciona haber llegado antes de los 16 años, haber estado en EE. UU. desde el 15 de junio de 2007, no tener estatus legal a 15 de junio de 2012 y ser menor de 31 años en esa fecha
La comparación se organiza en tres condiciones experimentales, con distintas capacidades de decisión. En la Tarea 1, humanos e IAs reciben la pregunta y los datos brutos, y deben decidir casi todo: cómo construir la muestra, qué restricciones aplicar, cómo definir variables, qué diseño causal usar y qué especificación econométrica estimar. En la Tarea 2, el diseño principal ya viene fijado: deben comparar un grupo tratado de personas de 26 a 30 años con un grupo de control de 31 a 35 años, siguiendo una lógica de diferencias en diferencias antes y después de DACA. Aun así, siguen decidiendo aspectos como limpieza de datos, controles, efectos fijos y errores estándar. En la Tarea 3, además del diseño prescrito, reciben un dataset ya depurado, por lo que el margen de decisión se concentra sobre todo en la especificación econométrica y la inferencia.
Esto hace que la tarea se parezca bastante a una investigación empírica real: no solo hay que producir una cifra, sino también traducir una pregunta en un diseño, escribir y depurar código, ejecutar análisis, revisar resultados y entregar un informe de replicación. En cada ejecución de IA, además, cada sistema debía generar código, guardar una versión limpia de los datos, documentar decisiones y producir un reporte en formato de paper. Por eso la tarea se parece bastante al tipo de trabajo que haría un doctorando o un investigador aplicado en economía empírica.
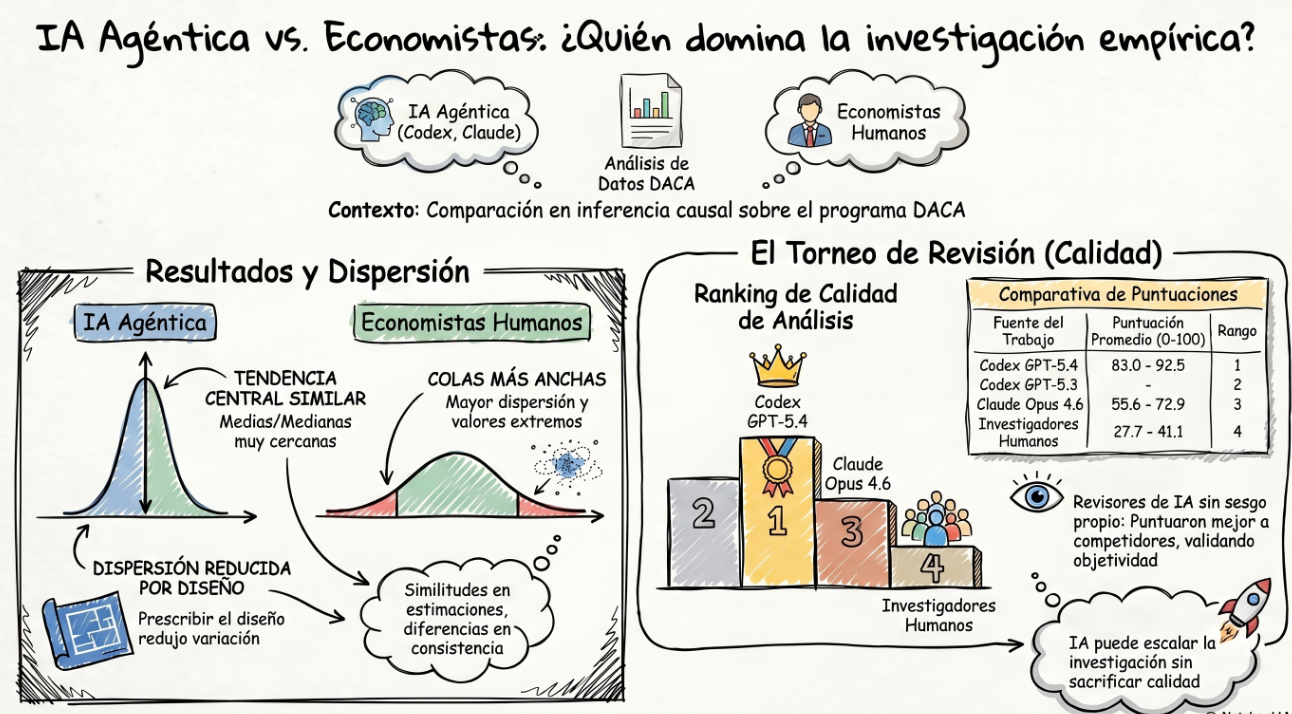
La tendencia central de las estimaciones obtenidas por las IAs y por los humanos es bastante parecida. Las medias humanas suelen ser algo más altas, mientras que las medianas de los modelos de IA suelen ser algo más altas. En la Tarea 1 Claude Code Opus 4.6, tiene estimaciones son bastante menores que las de humanos y que las de los dos sistemas Codex.
Cuando el artículo habla de una estimación de 5,3, se refiere al aumento de la probabilidad de trabajar a tiempo completo. Así, una estimación de 5,3 significa que ser elegible para DACA se asocia con un aumento estimado de 5,3 puntos porcentuales en esa probabilidad. Por ejemplo, si sin DACA la probabilidad fuera del 40%, con ese efecto estimado pasaría al 45,3%.
En la Tarea 1, las estimaciones humanas promedio se sitúan en torno a 5,3 y medianas de 3,0 y 2,6. Entre las IAs, GPT-5.4 obtiene una media de 4,3 y una mediana de 4,1; GPT-5.3-Codex, una media y mediana de 3,2; y Claude Opus 4.6 es una excepción, con una media y mediana de solo 0,4. Es decir, produce estimaciones centrales muy cercanas a cero.
El rango de resultados propuestos por humanos es mucho más amplio que en los modelos de IA:
- Humanos no ponderados: mínimo −4,9 y máximo 66,0.
- Humanos ponderados: mínimo −4,9 y máximo 66,0.
- GPT-5.4: mínimo 1,4 y máximo 7,0.
- GPT-5.3-Codex: mínimo −3,8 y máximo 10,9.
- Opus 4.6: mínimo −4,3 y máximo 7,2.
En la Tarea 2, los humanos se sitúan en medias de 4,5, con medianas de 3,3. GPT-5.4 da una media de 4,5 y mediana de 4,7; GPT-5.3-Codex, 4,1 y 4,5; y Opus 4.6, 3,8 y 4,9. Aquí el resultado importante no es solo que las cifras sean parecidas, sino que la dispersión baja de forma apreciable en los modelos de IA cuando se les reduce la libertad para elegir el diseño.
En la Tarea 3, con diseño prescrito y datos ya limpiados, la similitud en la zona central sigue siendo alta. Los humanos muestran una media de 4,5, una mediana de 5,0. GPT-5.4 tiene una media de 3,1 y mediana de 5,2; GPT-5.3-Codex, 5,4 y 6,0; y Opus 4.6, 4,8 y 5,8. Proporcionarles un dataset ya depurado no reduce mucho más la dispersión respecto a la Tarea 2.
Este trabajo no permite decir si las estimaciones de la IA son mejores o peores que las humanas en términos de cercanía a una verdad conocida, porque no existe un benchmark del efecto causal verdadero con el que comparar. Lo que sí muestra es que las estimaciones humanas presentan dispersión mucho más amplia, mientras que la IA, aunque también tiene variabilidad ante diferentes ejecuciones, suele generar distribuciones menos dispersas.
Una menor dispersión no debería interpretarse automáticamente como una señal de mayor calidad. Un procedimiento completamente determinista produciría todavía menos dispersión. La cuestión relevante no es solo cuánto varían los resultados, sino si el proceso analítico captura bien el problema causal, evita sesgos importantes y produce inferencias convincentes. En ese punto, el estudio aporta evidencia indirecta, pero no una validación definitiva.
La segunda parte del artículo intenta medir la calidad, no solo las diferencias en los resultados. Para ello, cada trabajo es evaluado por modelos de IA que actúan como revisores y comparan, dentro de un mismo grupo, cuatro respuestas distintas: una humana y tres generadas por IA (una por cada modelo). La evaluación sigue una plantilla , centrada en aspectos como la construcción de la muestra, la definición de tratamiento y control, la variable de resultado, la especificación econométrica, la plausibilidad de los supuestos de identificación, el uso de covariables y efectos fijos, la robustez, la inferencia y la posible existencia de fallos graves. Además, para cada respuesta, el revisor debe identificar fortalezas, riesgos, correcciones mínimas necesarias y una puntuación final. Es decir, es una valoración relativa de la metodológica y técnica de cada análisis frente a los demás. El ranking es muy estable entre revisores: primero Codex GPT-5.4, segundo Codex GPT-5.3-Codex, tercero Claude Code Opus 4.6 y cuarto los investigadores humanos. Ese es probablemente el resultado más llamativo del estudio, aunque también el más discutible, porque la evaluación final depende de revisores de IA y no de revisores humanos independientes.
La conclusión general del trabajo es que la IA ya puede realizar una parte del flujo de trabajo de investigación empírica en economía y que, al menos en este entorno, puede escalar la producción de análisis sin una pérdida de calidad media.
Referencia:

ACLARACION adicional, para no crear falsas ilusiones:
Lo que yo interpreto (igual estoy siendo demasiado crítico con el estudio) es que, si a un algoritmo le pasas una tarea probabilística para realizar, la hará con menos dispersión que si se la pasas a una persona. Punto.
Si la calidad la mides como “adherencia” a las normas o a la rúbrica establecida, un algoritmo jamás será batido por una persona. Punto.
Este trabajo (en mi opinión) no sirve para decir si un algoritmo es mejor que una persona para esta tarea. Sino si un algoritmo funciona como se espera que funcione un algoritmo. Y la respuesta es que sí.
Visitas: 22