Ya he completado las tareas. Tanto la “obligatoria” de presentar los papeles en ANECA, como la voluntaria de hacer una reflexión personal (Rellenar sexenios de investigación: mi propuesta para transformarlo | Blog de Juan A. Marin-Garcia).
Voy a compartir mi reflexión personal del proceso, si me ha servido para algo y las sensaciones que me han ido provocando las diferentes decisiones que he ido tomando.
Empecemos por algunos hechos:
- Tengo mucha producción. Me refiero a que tengo más de 7 posibles aportaciones (5 principales más dos sustitutorias). Eso es una ventaja porque me permite elegir. Es, al mismo tiempo, un fastidio porque me obliga a perder el tiempo tomando las decisiones sobre qué descartar. Decisiones que no son sencillas porque, al menos, hay 13 o 14 artículos con claro potencial. Luego hay varios artículos más que claramente no iban a ser candidatos -porque son protocolos y para mí confluyen con una de las aportaciones principales, o son de áreas ajenas al management o siempre fueron “artículos menores” que me interesaba escribir para dar cauce a una idea o para forzarme a aprender algo con rigor-.
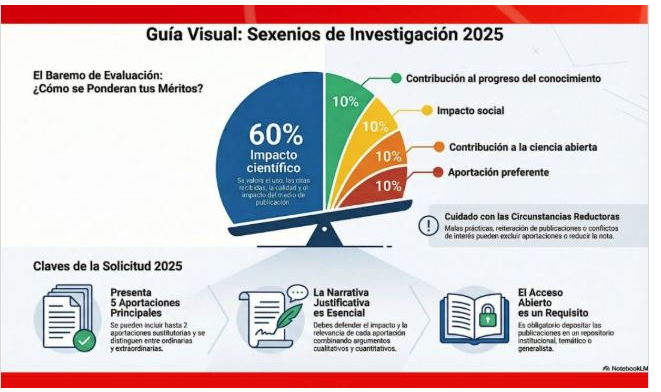
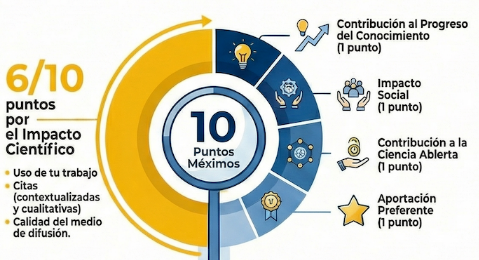
- Algunas de las circunstancias reductoras de puntuación afectan directamente a varios de mis trabajos.
Y pasemos ahora a mis inferencias, opiniones y percepciones. Para mí, estos son los “takeaways” que me llevo del proceso de reflexión, siendo consciente de que son solo el modo en que veo el asunto y, sin duda, están sesgados.
Algunos de los que yo considero mis mejores trabajos por lo que ha supuesto escribirlos, la contribución que yo creo que tienen en la academia y en la sociedad y que, además, han sido de los más citados (no me creo que las citas indiquen nada, pero supongo que para mucha gente este es un indicador imprescindible), no los puedo poner como meritos porque sería un suicido (directamente me van a poner un cero porque cumplen alguno o varios de los criterios de minoración de puntuaciones). Por ejemplo:
- Marin-Garcia, J. A., Vidal-Carreras, P. I., & Garcia-Sabater, J. J. (2021). The Role of Value Stream Mapping in Healthcare Services: A Scoping Review. International Journal of Environmental Research and Public Health, 18(3), 951. https://doi.org/10.3390/ijerph18030951
No me apetece jugármela a tener que defender mis méritos en una reclamación, de modo que voy a ser cauto y conservador y elegir como méritos los que creo que van a gustar al panel, no los que yo creo que realmente son mis mejores trabajos. Me he permitido la licencia de ser “irreductible” en una de las sustitutorias, donde he puesto una aportación de investigación sobre aprendizaje. Porque desde el primer sexenio me impuse el compromiso de poner siempre al menos una investigación docente en mis aportaciones:
- Aznar-Mas, L. E., Atarés Huerta, L., & Marin-Garcia, J. A. (2021). Students have their say: Factors involved in students’ perception on their engineering degree. European Journal of Engineering Education, 46(6), 1007–1025. https://doi.org/10.1080/03043797.2021.1977244).
De las 5 aportaciones principales, yo solo habría mantenido una o dos de ellas (y también habría puesto otra en lugar de una de las sustitutorias). ¿Por qué no lo he hecho? Porque me “he cagado”. Tengo la seguridad de que no lo iban a entender en la comisión y que peligraba el sexenio… que no pasa nada, ya tengo 3 sexenios, y un sexenio son solo 140 euros al mes de extra en la nómina. Es triste, pero me he vendido por 140 euros de mierda (que, además, no me hacen falta para llegar a final de mes, esa enorme suerte tengo).
¿Cuales hubiera puesto yo de no haberme “cagado”? Sin duda, habría puesto al menos dos contribuciones sobre las cosas que hicimos durante la época de COVID, en la que nos volcamos a dedicar horas y todos nuestros conocimientos para apoyar a los hospitales. A los que nos quisieron como colaboradores, y hasta que nos obligaron a dejar de colaborar con ellos desde las altas esferas (bueno, nunca les hicimos caso y seguimos desde la clandestinidad 😉 ). Gracias a ello, recibimos el premio “Luis Merelo y Más” del Colegio de Ingenieros Industriales de la Comunidad Valenciana. Muchas de las cosas que aprendimos entonces también las pudimos aplicar durante la catástrofe de la Dana del 2024. Como representativo de esta línea hubiera elegido estos dos trabajos:
- Marin-Garcia, J. A., Garcia-Sabater, J. J. P., Ruiz, A., Maheut, J., & Garcia-Sabater, J. J. P. (2020). Operations Management at the service of health care management: Example of a proposal for action research to plan and schedule health resources in scenarios derived from the COVID-19 outbreak. Journal of Industrial Engineering and Management, 13(2), 213. https://doi.org/10.3926/jiem.3190
- Redondo, E., Nicoletta, V., Bélanger, V., Garcia-Sabater, J. P., Landa, P., Maheut, J., Marin-Garcia, J. A., & Ruiz, A. (2023). A simulation model for predicting hospital occupancy for Covid-19 using archetype analysis. Healthcare Analytics, 3, 100197. https://doi.org/10.1016/j.health.2023.100197
Además, habría puesto mis artículos sobre guías para la difusión de la ciencia. Sinceramente creo que son de las cosas más útiles e interesantes que he hecho (aunque sea yo el único que piense eso):
- Marin-Garcia, J. A. (2021). Three-stage publishing to support evidence-based management practice. WPOM-Working Papers on Operations Management, 12(2), 56–95. https://doi.org/10.4995/wpom.11755
- Marin-Garcia, J. A., & Alfalla-Luque, R. (2021). Teaching experiences based on action research: A guide to publishing in scientific journals. WPOM-Working Papers on Operations Management, 12(1), 42–50. https://doi.org/10.4995/wpom.7243
- Marin-Garcia, J. A., Garcia-Sabater, J. P., & Maheut, J. (2022). Case report papers guidelines: Recommendations for the reporting of case studies or action research in Business Management. WPOM-Working Papers on Operations Management, 13(2), 108–137. https://doi.org/10.4995/wpom.16244
Sobre investigación docente habría elegido este, porque realmente es el trabajo que más transforma el aprendizaje de 60 futuros directivos-as cada año:
- Marin-Garcia, J. A., Garcia-Sabater, J. J., Garcia-Sabater, J. P., & Maheut, J. (2020). Protocol: Triple Diamond method for problem solving and design thinking. Rubric validation. WPOM-Working Papers on Operations Management, 11(2), 49–68. https://doi.org/10.4995/wpom.v11i2.14776
También habría incluido alguna aportación representativa de mi línea de investigación en Gestión de Recursos Humanos. Mi solicitud ha quedado demasiado sesgada hacia la Dirección de Operaciones. Por ejemplo habría incluido:
- Marin-Garcia, J. A., Bonavia, T., & Losilla, J. M. (2020). Changes in the Association between European Workers’ Employment Conditions and Employee Well-being in 2005, 2010 and 2015. Int J Environ Res Public Health, 17(3), 1048. https://doi.org/10.3390/ijerph17031048
Resumiendo, no me he atrevido a dejarme llevar por la interpretación que yo hago de cuál creo que es el espíritu de la norma. He preferido autocensurarme y hacer una solicitud estándar, del montón, doblegando mi espíritu crítico, mi creatividad, y mi compromiso con una pasión para encajar en el estrecho corsé de lo que creo (sin ninguna certeza) que se puntúa en mi campo científico. Esto me deja una profunda desazón y vergüenza. No ha sido una experiencia agradable el tener que pasar por esto. Y me deja preocupado. Si algo que no necesito es capaz de pervertir mi comportamiento, y hacer que me venda y me aleje de mis creencias solo por conseguir una métrica, estamos realmente “jodidos” en la academia.
Si no tuviera la seguridad de que me van a sobrar aportaciones y que, por lo tanto, puedo dedicarme a investigar lo que creo, en conciencia, que es lo que debo investigar, habría tenido una enorme presión por dejar de hacer las cosas en las que creo, para dedicar mi escaso tiempo solo a las cosas que me van a puntuar. Por suerte, yo abordo todo lo que hago como un proyecto de publicación de artículos, lo que me genera un volumen alto de opciones y permite que, cosas que sé desde el principio que jamás serán puntuables, puedan tener su oportunidad de existir y ser encontradas por potenciales lectores.
Mientras escribo esta entrada, me ha llegado al mi bandeja de entrada este anuncio de publicación de artículo:
- Baruch, Y., & Budhwar, P. (n.d.). Impact and management studies: Why making practical impact is not a core academic expectation. European Management Review. https://doi.org/10.1111/emre.70051
Ha sido providencial porque aborda muchas de las cosas que yo he estado pensando estas dos últimas semanas. Os dejo algunos apuntes a modo de trailer:
El artículo alerta sobre la creciente presión gubernamental para que la investigación demuestre un impacto práctico inmediato, lo que está erosionando la función fundamental de las universidades. Esta exigencia representa una ruptura con el modelo de universidad basado en la autonomía para la búsqueda libre del conocimiento.
El problema es tanto conceptual como metodológico. Por un lado, la naturaleza misma del trabajo académico en ciencias sociales genera impacto de forma indirecta y diferida: los académicos transforman la sociedad a través de sus estudiantes y del conocimiento que estos llevan al mundo profesional, un proceso cuyo valor se manifiesta a largo plazo. Por otro lado, la medición del impacto carece de criterios válidos y fiables, siendo prácticamente imposible establecer una relación causal directa entre una investigación específica y cambios sociales u organizacionales concretos.
Los autores no rechazan el valor del impacto práctico, sino su imposición como criterio central de evaluación académica. La creación de conocimiento, el rigor intelectual y la libertad académica deben constituir el “imperativo” de la universidad, mientras que la aplicación práctica inmediata puede ser un resultado deseable pero no una obligación. Invertir esta prioridad, convirtiendo el impacto como motor principal de la actividad académica, supone desviar recursos intelectuales de la generación de conocimiento original hacia la demostración de utilidad inmediata, comprometiendo así la esencia misma de la institución universitaria.
Visitas: 151