Marco AIR para uso responsable de IA: útil pero revelador de nuestras inconsistencias
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
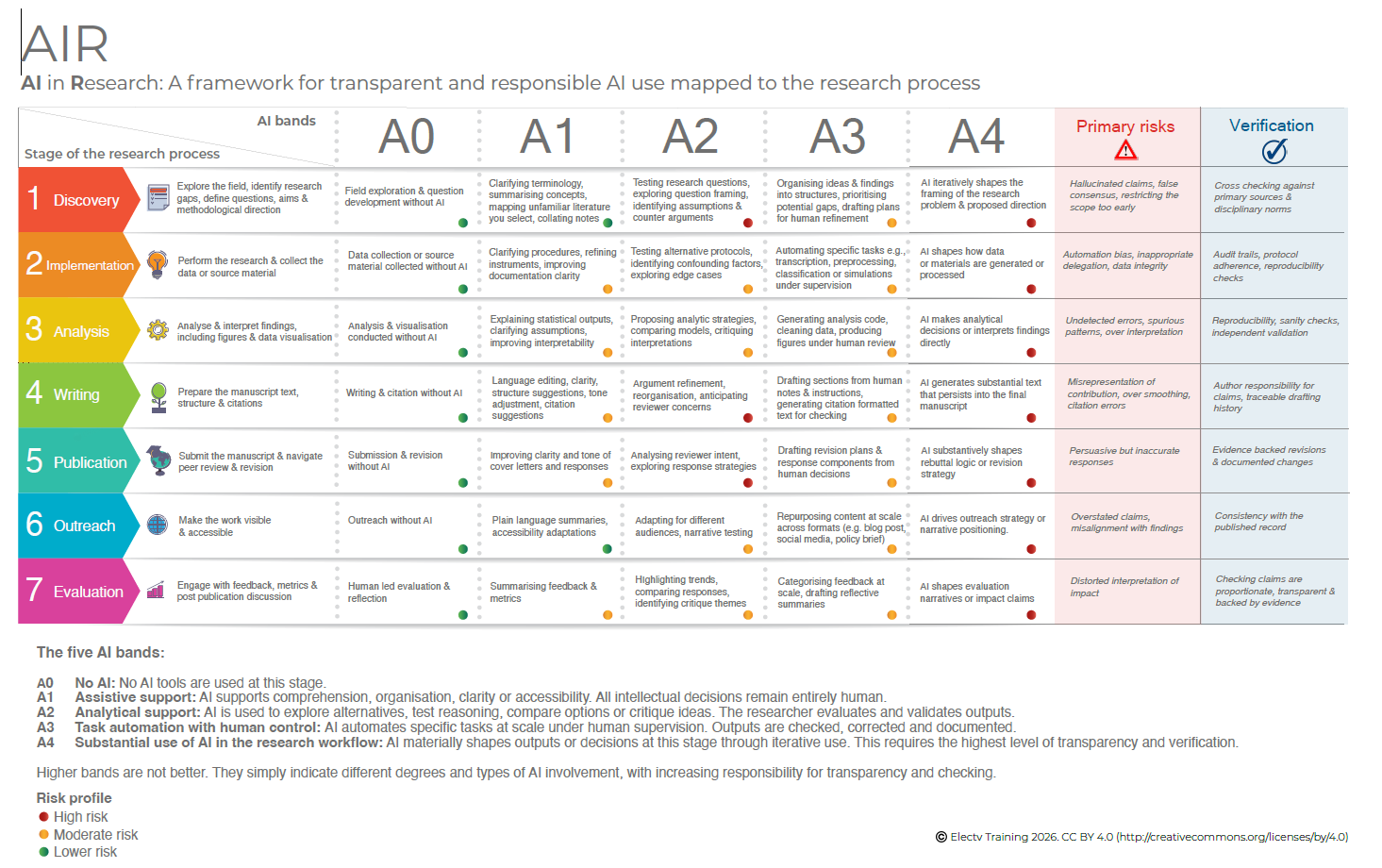
Creo que es muy útil para resolver algunas de las dudas que surgen en mis charlas sobre IA generativa en Research.
Con esta tabla, en menos de 5 minutos, puedes informar con transparencia sobre el uso que has hecho de la IA y las verificaciones que has realizado (la última columna) para estar seguro de que lo etiquetado como riesgo moderado no representa ningún “concern” para la validez de tu trabajo.
Intentar justificar que lo etiquetado como riesgo elevado no te afecta podría dar lugar a un artículo por cada una de las casillas de la columna A4.
Y este es el talón de Aquiles de todo esto… si alguien te obliga a demostrar punto por punto que estás exento de riesgos y sesgos, igual necesitas uno o dos años de trabajo para justificar adecuadamente cualquier artículo… incluso los que has escrito completamente “a mano” sin ayuda de ninguna IA generativa.
Es un poco sorprendente el doble rasero que se aplica, no pidiendo ninguna justificación si lo haces tú solito (proyectando todas tus torpezas y sesgos implícitos), y abrumándote con justificaciones si te apoyas en IA generativa. No, si no está prohibido que la uses, pero si dices que la usas, debes invertir una burrada de horas de trabajo para justificar “adecuadamente” que el uso ha sido correcto.
¿Alguien me ha preguntado alguna vez si he usado correctamente SPSS en los artículos que he escrito en los últimos 30 años? ¡Pero si, las veces que intento adjuntar la sintaxis, los revisores me dicen que quite esa información porque les “despista” y hace innecesariamente largo el artículo!
Young, J. (2026). AIR: AI in Research – A framework for transparent and responsible AI use mapped to the research process (Version 1). figshare. https://doi.org/10.6084/m9.figshare.31268020.v1
Esta es mi conclusión, contraría a la de las personas que han escrito este artículo. Para mí, 0.4 puntos de diferencia en una escala de 1 a 7 sobre algo complicado de medir y con mucha subjetividad, me parece que es más bien lo contrario, un nivel de acuerdo excepcional. Tsirkas, K., Chytiri, A. P., & Bouranta, N. (2020). The gap in soft skills perceptions: A dyadic analysis. Education and Training, 62(4), 357–377. https://doi.org/10.1108/ET-03-2019-0060
Luego hay un “temita” que normalmente me desespera un poco y es el de los gráficos falsos (si, vale no son falsos, pero están trucados). Este radar chart es un ejemplo clarísimo. El truco es que no pones el principio y el final de los ejes del gráfico en el nivel mínimo y máximo de la escala respectivamente (que sería un 1 y un 7). Sino que el centro lo pones en un valor arbitrario, por ejemplo, el 4, y el tope de la escala lo pones en 6,5 (otro valor arbitrario). De modo que cada “curva de nivel” ya no representa un punto sino, quizás, 0,2 puntos y entonces las diferencias visuales quedan magnificadas. Por supuesto, si no pones los números el impacto es mayor. Aunque los pongas, el truco sigue funcionando porque el espacio visual impacta más que el hacer una resta entre 5.76 y 5.29 (por ejemplo, para trabajo en equipo). Si queréis engañar o confundir a la audiencia es la mejor forma de hacerlo, pocas personas se darán cuenta del truco y el impacto es ¡Wohw, vaya diferencia más brutal!
Para ir avanzando en mi modelo de “second brain”, estaba reflexionando sobre el procesos que sigo para extraer la información y he tenido que hacer un alto para aclarar términos.
La literatura (ver referencias) suele identificar diferente cantidad de etapas en el proceso de análisis de contenido, y darle nombres distintos a etapas que tienen muchas cosas en común. Por eso he dedicado toda la mañana a integrar la información en una tabla en la que lo relevante es la definición basada en tareas. Que haya estado más o menos acertado al capturar los significados o al agrupar los sinónimos, creo que es mucho menos relevante.
Term used*
Definition (qué se hace)
Chunk (free coding; open coding; free text; annotation; quotation)
Extraer fragmentos de información; seleccionar la “quotation/annotation” sin añadir ningún “code” es el equivalente a resaltar o subrayar un fragmento de texto (“chunk” en el lenguaje de IAgen). Representan la voz de la persona informante sin interpretación del investigador-a
Open Coding (1st-order concept, initial coding)
Selección y refinamiento de los códigos para que representen los temas principales de los chunks, sus similitudes y diferencias. Interpretación conceptual de los open coding y decidir cómo agruparlos bajo temas más abstractos. Emergen nuevos conceptos que ayuden a describir, entender los chunks, o a rellenar gaps entre chunks
Focused coding (axial coding, 2nd order themes)
Crear una jerarquía o relación entre los focused codes, añadiendo categorías, y creando una integración conceptual a través de las relaciones entre temas y/o conceptos que explica el cómo, el porqué o las causas (que viene siendo una representación gráfica de la teoría)
Crear una jerarquía o relación entre los focused codes, añadiendo categorías, y creando una integración conceptual a través de las relaciones entre temas y/o conceptos que explica el cómo, el por qué o las causas (que viene siendo una representación gráfica de la teoria)
* Incluyo entre paréntesis sinónimos utilizados por diferentes tradiciones
Estas instrucciones han sido creadas en julio de 2025, es probable que en el futuro las pantallas u opciones que se muestren no coincidan con las actuales.
Me preocupan los mensajes ¿subliminales? relacionados con la Inteligencia Artificial que inundan las redes. Los argumentos comerciales que más utilizan las plataformas y empresas que están desarrollando modelos de inteligencia artificial generativa son del tipo:
“No leas tú, ya te resume la IA los documentos”
“Procesa 100 artículos científicos en 30 minutos”
“Disfruta de la experiencia de estar en varias reuniones simultaneas y no te pierdas nada con nuestros resúmenes automáticos”
Esto lo hacen prácticamente todas, empezando por Microsoft cuando vende su copilot, perplexity, Consensus, Scite y otras plataformas supuestamente entrenadas para dar soporte a la investigación. Incluso en los videos de promoción de ChatGPT y similares cuando hacen sus lanzamientos.
Pero ¿Dónde queda el aprendizaje? ¿Dónde la reflexión?
Necesitamos un aprendizaje profundo para poder evaluar críticamente las salidas de una inteligencia artificial generativa. Sin embargo, la corriente nos lleva hacia un pasar superficialmente por todo. Lo que me preocupa es que veo intención detrás de la creación de la corriente.
Llevo 4 meses sometiendo a diferentes modelos/plataformas a casos de uso reales que me enfrento en mi tarea como investigador en el área de management. Cada vez que tengo que realizar una tarea susceptible de se copilotada por una Inteligencia Artificial generativa, la pruebo en las 6 alternativas (me he suscrito a la version “pro” de todas ellas para poder compararla en su “mejor versión”).
Mis casos de uso recorren tareas tan diversas como plantear investigaciones nuevas, dar respuesta a criticas de revisores/as a mis envíos a revistas, ver el estado actual de investigación, extraer definiciones contrastadas avaladas por citas “top”, asesor metodológico para análisis complejos, soporte para código python o R para análisis, soporte para creación de páginas web para captura de datos, reformulación de transcripciones de entrevista, anonimización de nombres (entity recognition) en entrevistas o campos abiertos de encuestas,….
Además, los he usado varias veces para cada tarea (mínimo 5 o 6 veces, algunas más de 30 veces durante estos cuatro meses)
En las plataformas como perplexity, consensus, scite o scispace no he sido capaz de saber cual es el modelo que usan de base. Todas ellas lo han “fine-tuneado” pero no se sobre que modelo han partido.
En mi experiencia, el modelo por excelencia para soporte a tareas de investigación es Claude3.5-sonnet. Ninguna de las otras plataformas se acerca en rendimiento.
Puedes acceder desde Anthropic https://claude.ai/login?returnTo=%2F%3F o desde https://poe.com (mi favorita)
Pd: si no tienes dinero para pagar varias suscripciones, mi consejo es que lo inviertas en Poe.com (o, como segunda opción, en Anthropic). Si tines dinero para pagar varias, compra solo la de Poe.com y te gastas el resto tomando algún aperitivo con tus amigos/as.
Pd: mi ranking no puede extrapolarse para otros usos no relacionados con tareas de investigación. También podéis alegar que mis casos de uso son “muy particulares” y no os representan. Si no os convencen mis resultados, comprobadlo aplicando a vuestros casos de uso.
En la última sesión de una de mis asignaturas, los estudiantes identificaron los siguientes problemas que han experimentado trabajando en equipo (en entornos de educación universitaria). He parafraseado e integrado las ideas (y no me he podido resistir, he puedo algunos comentarios míos en corchetes cuadrados con color diferente):
Personas que no se implican o toman en serio el trabajo a realizar ([incumplen las fechas acordadas, se aprovechan del trabajo de otros, polizón/”free-riders”])
Personas extremadamente críticas hacia otras opiniones que no sean las suyas propias
Personas que te presionan continuamente para que completes tu tarea ([¿en serio? ¿esto es un problema o el problema es no completar las tareas cuando se acordó?])
No querer reunirse para realizar el trabajo (dificil coordinar horarios, poco interés, sobrecarga de otras tareas, o cualqueir otro motivo), se preparte la tarea y luego se junta ([yo a esto le llamo “grupos grapadora”, no hay interacción , ni interdependencia, ni sinergia, ni aprendizaje cruzado…Simplemente se ven el día del reparto y el dia que “grapan” las partes del informe a entregar])
No mostrar empatía o interesarse por lo que necesitan las demás personas del equipo. Hacen su tarea y no se preocupan de los problemas que puedan tener otras personas del grupo
Reparto no equitativo de tareas. Algunas personas puede acabar haciendo mucho más trabajo que otras ([seguramente muy vinculado al problema 1, y agravado con 4 o con 5])
Problemas de comunicación dentro del equipo
Problema de socialización en el grupo (desponocimiento de las otras personas)
Y sospechan que los principales problemas que se pueden presentar cuando trabajen en una organización sean:
Falta de implicación
Presión de la persona que ocupa el mando para que el trabajo se cabe cada vez antes
No tener claros los objetivos
Crear subgrupos dentro del equipo y que funcionen sin comunicarse (de manera independiente y cada uno remando en una dirección diferente o haciendo tareas repetidas mientras otras se quedan sin hacer)
Conflictos originados por una relación personal entre personas integrantes de un mismo grupo
A partir de esta información me gustaría responder a estas preguntas:
¿Son similares los problemas a los que se enfrentan como estudiantes que a los que se enfrentarán como profesionales en las organizaciones?
¿Qué dice la investigación previa sobre la prevalencia de estos problemas o cómo resolverlos?
¿Cómo afecta el trabajo remoto a estos problemas? ¿Los aumenta, los mitiga, o simplemente no afecta ni en un sentido ni en otro?
Igual me equivoco. Mi sensación es que los sexenios actuales, al menos en el campo donde está mi área de conocimiento, están mandando este mensaje:
“Si no eres capaz de publicar en una revista de muy alto nivel (no que realices una investigación de muy alto nivel) 5 veces en 6 años (o en una de altísimo nivel 3 veces en 6 años), deja de investigar y dedícate solo a impartir docencia”
En otra entrada de mi blog explico que, en mi caso, impartir 32 créditos (320 horas de clase presencial) implican 1500 horas de trabajo. Obviamente esta estimación es si lo haces bien: te documentas; actualizas contenidos, casos y actividades; haces evaluación formativa dando feedback y feedforward a los estudiantes (bien individual, bien colectivamente); etc. Con 32 créditos queda muy poco margen para hacer una investigación potente. O si lo prefieres, es probable que el esfuerzo de tu investigación drene tu docencia, que se resentirá drásticamente.
Esto me crea confusión y no tengo clara cuál es la finalidad o función de los sexenios en el panorama de la investigación en España. Siempre había creído que eran un complemento retributivo. Me basaba en las batallitas que me contaron los más viejos del lugar (aquellos que vivieron en primera persona la publicación del BOE que creaba los sexenios) y tras leer los BOE fundacionales de los sexenios.
Sin embargo la utilización que se hace de los mismos actualmente me parece que encaja más con un premio competitivo de excelencia. Obviamente, las personas solicitantes no compiten con otras solicitantes. No hay un cupo de sexenios a conceder en cada convocatoria. Pero sí se compite por los escasos huecos para colocar un artículo en una revista puntera. O por conseguir ser citado, que también son unos huecos limitados (algunas revistas, o algunos revisores, imponen límites al numero de citas. Yo creo que se equivocan, pero ahí están, entre las revistas que acumulan mayor número de citas). Esta competición es contra otras personas que investigan en todo el mundo y se basa en posiciones o ránking o estadística de distribución de citas por artículo.
Por lo tanto, se me ocurren dos posibles funciones que podrían estar en la base de los sexenios. Quizás haya más, pero ahora sólo se me ocurren estas dos (y como veréis es difícil que puedan cumplir ambas, porque el modo de ponerlos en marcha es radicalmente diferente dependiendo de la función que quieres que cumplan):
A) Sexenios es una herramienta de motivación del personal docente e investigador de las universidades españolas, y puede servir, además, como una comprobación rápida de que el trabajo de investigación de 6 años es “digno”. En ese caso, es necesario: a) fijar el norte de qué es lo que se quiere potenciar y b) poner un conjunto de métricas alineadas con ese objetivo (lo que se considera un trabajo digno). En este caso, los indicadores deben ser objetivos, predecibles y fijos antes de que la persona haga la investigación. Si se cambian, deben mantenerse las dos “métricas” durante 6 años y usar la que más favorezca a la persona solicitante en ese periodo. El sistema debería ser transparente, sencillo de entender y totalmente automatizable. Se puede hacer un simulador pues, en esencia, la concesión es una decisión totalmente programada y no debe haber sorpresas, ni ambigüedades. Lo que se busca es motivar y crear pasión en un conjunto amplio de personas (miles en total, cientos en cada comisión). No se busca cabrearlas, ni frustarlas, ni ansiarlas. Si se usan evaluadores humanos con criterios subjetivos es sólo para valorar reclamaciones o para casos poco comunes.
B) Sexenios es una evaluación de la calidad de la investigación de la persona solicitante, con un criterio fundamentalmente de excelencia. Aquí encaja mucho una evaluación diversa y rica. En línea con DORA, usando un panel de expertos que pueden valorar, cualitativamente, CADA aportación de CADA solicitante y su historial en el periodo evaluado. Siempre será una evaluación impredecible (aunque sea transparente) porque se basa en juicios humanos (no algoritmos). No tengo claro si, el volumen de solicitudes permite este tipo de evaluación (no es solo que aumeten recursos, si lo hacen hay que alinear criterios de todavía más evaluadores para que no haya agravios comparativos). Tampoco sé si, en este caso B, sería aceptable establecer las métricas y los niveles “a posteriori” (cambiarlos cuando la persona solicitante ya ha realizado su investigación). Desde luego, sera mucho menos dañino que en el caso A) (motivación). Porque se asume que la excelencia es una competición con unas expectativas diferentes a la de la motivación de la fuerza laboral.
En primer lugar, me gustaría aclarar que el impacto de un articulo mucho más que medir sus citas en un determinado proveedor de servicios de indexación de revistas científicas. Lo que pasa es que contar las citas es sencillo (si te conformas con los datos que te proporciona Clarivate/WOS, Scopus o Google Scholar), lo que no quiere decir que sea relevante, ni sea “verdadero” impacto. Es la versión de impacto más sencilla y, a veces, la única que podemos calcular de manera práctica.
Con esto en mente, la pregunta que intentare resolver en esta entrada es ¿cómo saber si un artículo científico publicado es más citado o menos que los artículos similares?
De nuevo tengo que hacer una suposición que no es menos drástica y no genera menos sesgo que la de asumir que impacto = citas. Se trata de asumir que un artículo es similar si:
Se ha publicado el mismo año. Aunque no es lo mismo que se publique en enero, que en diciembre, o que haya estado años en “advanced online” sin fecha definitiva de publicación… Sobre todo cuando la fecha de publicación es reciente, porque aún teniendo el mismo año de publicación un articulo puede estar expuesto al circuito de citas el doble, triple o incluso cuatro veces más de tiempo que otro (de modo que muy similares no serían)
Son del mismo “tema” o “área de conocimiento”. La idea de fondo es que hay áreas o comunidades científicas donde los circuitos de maduración de citas (el tiempo habitual que se tarda en ser citado, el numero habitual de citas recibidas y el tiempo que tardas en pasar a ser difícilmente citable por “antiguo”) es muy diferente. El problema es que tanto Clarivate/WOS como Scopus tienen un método un tanto cuestionable (no solo por su poca transparencia, sino por sus patentes fallos de clasificación) de decidir en qué área colocar un articulo y, por lo tanto, establecer el conjunto de artículos similares con el que comparar
Por último, debemos asumir que disponemos de acceso a plataformas de pago que hacen el trabajo por nosotros (no conozco ningún servicio gratuito que permita realizar lo que voy a comentar en esta entrada). O pagas una suscripción a Clarivate/WOS o a Scopus, o la paga la institución para la que trabajas. Pero, al menos con mis conocimientos, esto no lo puedes hacer sin rascarte el bolsillo o que alguien se lo haya rascado por ti (o hayas pirateado o usado materiales al margen de las condiciones de uso exclusivo que permiten Clarivate/WOS o Scopus).
En este contexto, y solo en este contexto, es posible dar algunas respuestas a la pregunta.
Advertencia: el procedimiento, enlaces y pantallazos se corresponden a cómo resolver esto en octubre de 2021. Como las plataformas cambian con relativa frecuencia, es posible que las rutas o ubicación de las opciones sea completamente diferente el día que vayas a intentar hacerlo tu.
Algunas aclaraciones previas: El FWCI (Field Weight Citation Indez) de SCOPUS es similar al CNCI (Category Normalized Citation Impact) de WOS, el CNCI también lo han “percentilizacion” en el beamplot. Ambos son valores FWCI y CNCI son referente a la media, no son numero de desviaciones estandar respecto a la media, sino cuantas veces las citas de un articulo son respecto a las citas promedio de un articulo equivalente (1 es igual que la media, 2 el doble que la media, 0,5 la mitad que la media). Son valores que van desde 0 a infinito. FWCI y CNCI no suelen coincidir porque el conjunto de artículos que se considera equivalente son claramente distintos. Cada “agencia” agrupa las revistas y los temas de formas distinta y, además ponen parámetros distintos para la agregación y periodo de años.
Primera Opción: las herramientas de indices de impacto que proporciona la suscripción de recursos científicos de FECYT
Estas tablas se actualizan una vez al año (sobre noviembre o diciembre) y sólo están disponibles hasta 3 años antes del momento en el que buscas (pues se considera que con menos tiempo, la posibilidad de recibir citas es muy escaso y las tablas no tendrían mucha utilidad, ni fiabilidad). En cualquier caso, si un articulo publicado hace menos de 3 años ya mejora los indicadores de los que aparecían hace 3 años, es muy buena señal de que tiene un “impacto en citas” que se podría considerar excelente (o al menos superior a la media de articulo que llevan mucho mas tiempo en el “expositor”).
Ten en cuenta de que hay tablas para WOS y tablas para Scopus. Porque cada una de ellas se crea con una fuente de datos diferente y con una metodología de agrupación por area temática muy, muy, pero que muy diferente (no te comparas con el mismo conjunto de artículos en WOS que en SCOPUS). Podréis preguntarme “si me salen datos muy diferentes, ¿cual sería el más adecuado para usar en “mi área””. La respuesta sencilla, es: si miras las citas en WOS usa la tabla de WOS y si las miras en Scopus, pues la de Scopus. Pero si lo que te pasa es que cuando comparas WOS te sale muy bien y cuando comparas Scopus te sale muy mal (que tienes menos citas que el promedio), o al revés. Entonces no me atrevo a dar una respuesta más allá del depende. Lo que si es cierto (eso es un dato objetivo) que, la cobertura de revistas del área de ciencias sociales y en especial en los campos relacionados con la administración de empresa (management), a fecha de 2021, es mucho mayor y mejor en Scopus que en WOS. Además, en scopus hay una división mucho más específica por sub-áreas dentro del campo de administración de empresas (Marin-Garcia y Alfalla-Luque, 2018). Pero “hasta aquí puedo leer”. Que haya más cobertura de revistas o más clasificaciones no quiere decir que las agrupe mejor (quizás las agrupe igual de mal que WOS). Resolver esto daría para un artículo científico (animo a quien quiera a que lo haga y si no sabéis a qué revisa mandarlo, en JIEM o en WPOM estaríamos encantados de poder evaluarlo).
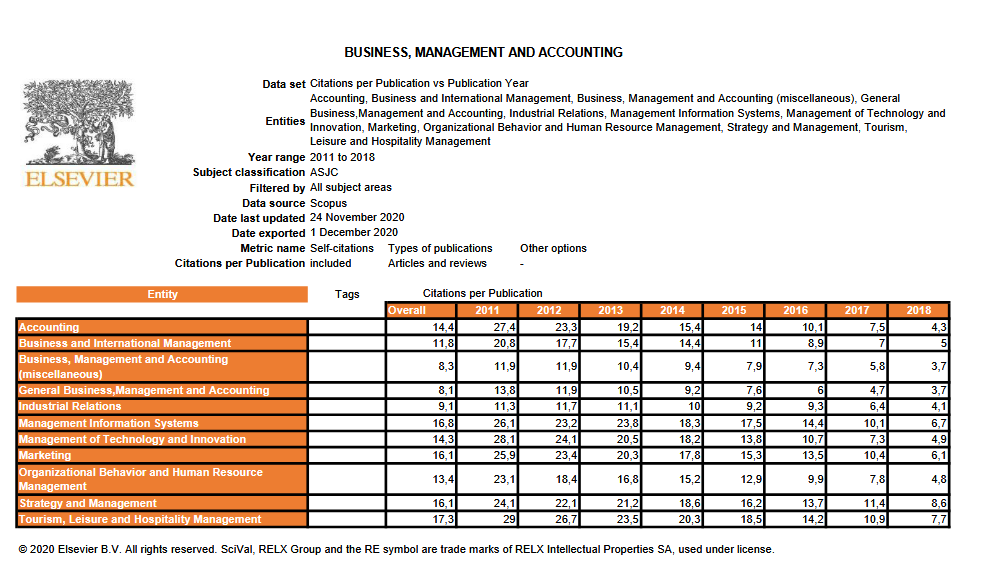
Además en cada una de las dos situaciones anteriores tienes dos tablas. En la primera tienes los “descriptivos” de las citas promedio recibidas por los artículos científicos publicados en determinados años, en cada área. En la segunda, para calcular el promedio se han incorporado también “conference proceedings“. Yo, personalmente, creo que solo tiene sentido la primera… pero si alguien se ha tomado la molestia de hacer dos tablas por algo será (como decía “La Bombi” en los casposos años del 1-2-3).
Esta es la información que proporcionan las tablas de citas. Tangase en cuenta que Dirección de Operaciones (Operations Management) no existe como campo, de modo que supongo que hay que considerar los “miscellaneous de business” o business en general como área de comparación. Pero oye, igual a otras personas les parece mejor otra cosa
Vaya… quizás tendría que haber pedido permiso a Elsevier para publicar esta foto.. Bueno, cuando tenga tiempo me dedico a escribir un párrafo que resuma algo de la información y pixelo esta tablaSi, WOS, con vosotros también lo haré… pero cuando tenga tiempo.
Segunda Opción: las métricas a nivel de articulo que proporcionan WOS o Scopus
Scopus lleva años (al menos desde 2018) publicando el “citation benchmarking” y el “field-weighted citation impact” , que se definen y calculan como se muestra en la figura (si quieres más información: Learn more about Article metrics in Scopus).
Definición del F-W citation impact de Scopus
Citation benchmarking
Esta información aparece en la página del articulo (cuando pinchas sobre el título del artículo en los resultados de una búsqueda para que te muestre la información completa). Hace un tiempo era en la parte lateral derecha, ahora está en la parte inferior de la páginas después del resumen… dentro de un tiempo estará en otro sitio.
Junto con el Field-Weighted citation impact (recordad, 1 es que está mas citado de lo esperado) se puede ver el Citation Benchmarking: percentil correspondiente al número de citas del articulo cuando se compara con todos los articulos de scopus publicados en la misma fecha. En la figura, 6 citas en 2016 significa estar en el percentil 59%, lo que puede considerarse un impacto en citas notable dentro de Scopus.
he resaltado en azul oscuro la zona donde se ve la información
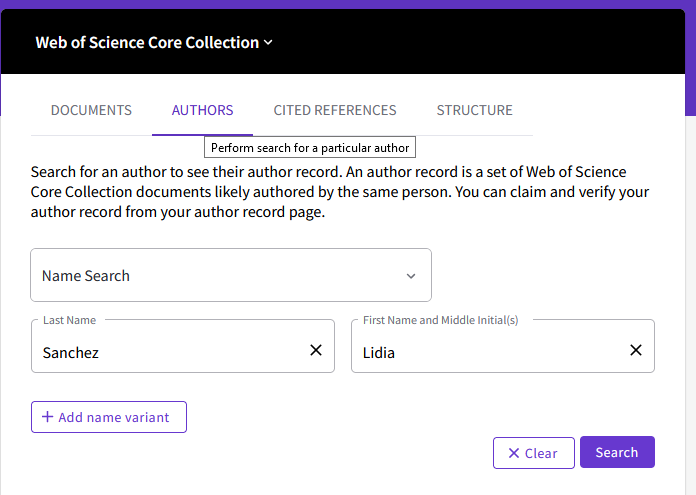
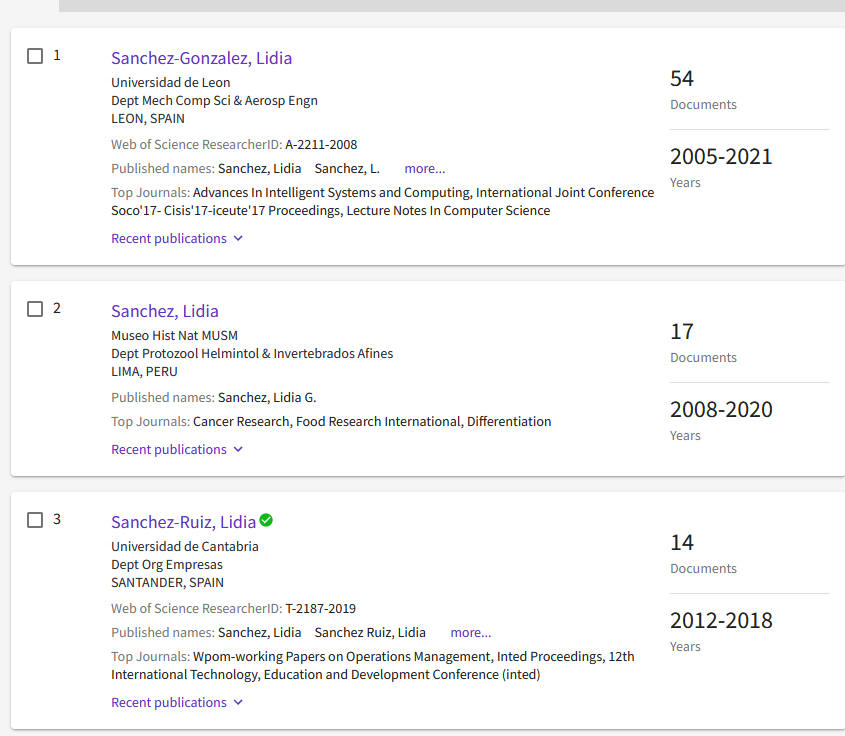
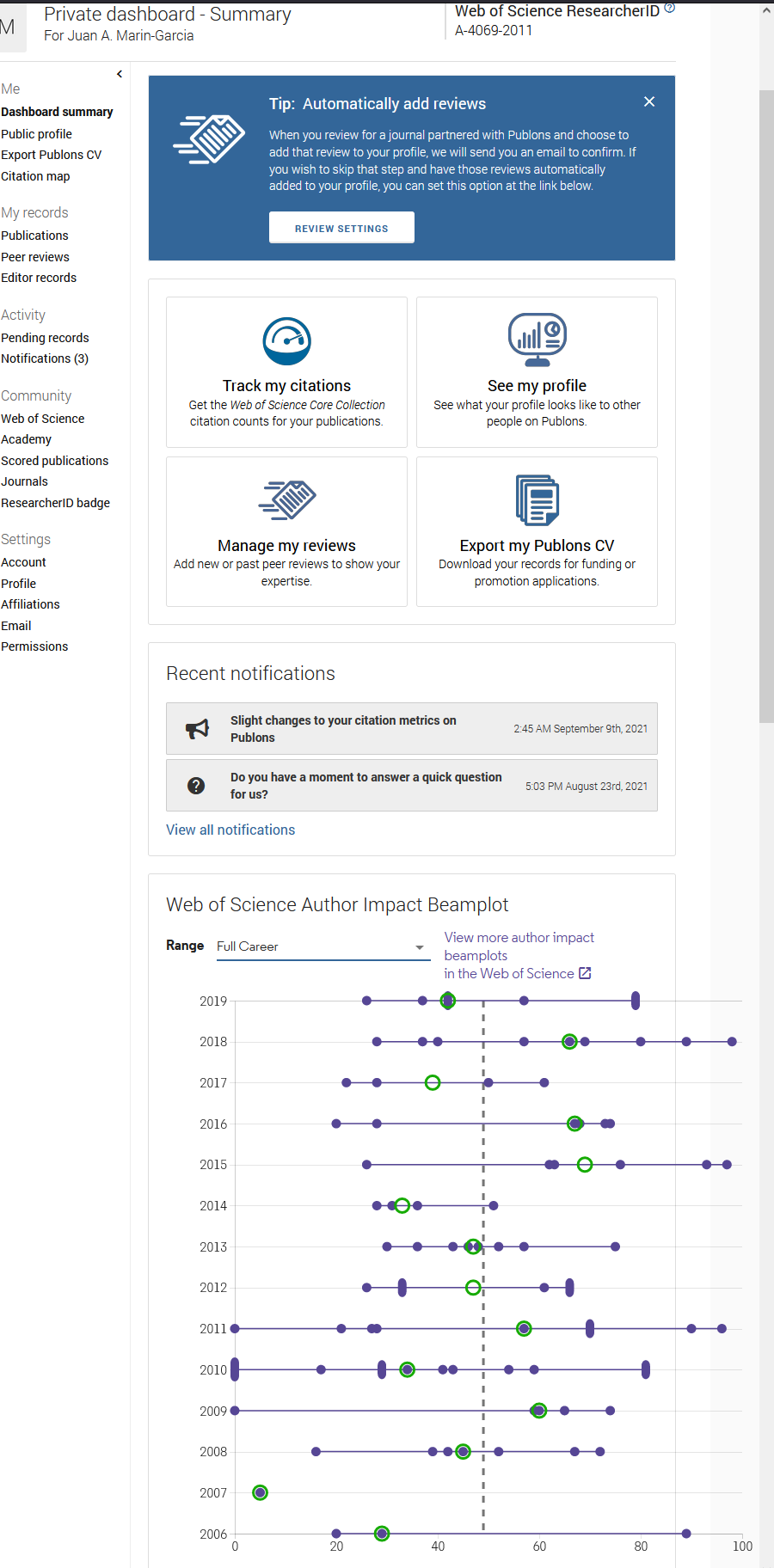
WOS se ha incorporado recientemente (2020) a las métricas a nivel de articulo con su “beamplot“. En estos momentos para acceder a estas métricas debes entrar en la página “personal” de cada investigador (Author Profile). Es decir, que no ves esta métrica cuando entras en la información del artículo. Tienes que localizar primero al autor-a
y luego pinchas en el vínculo que hay en su nombre
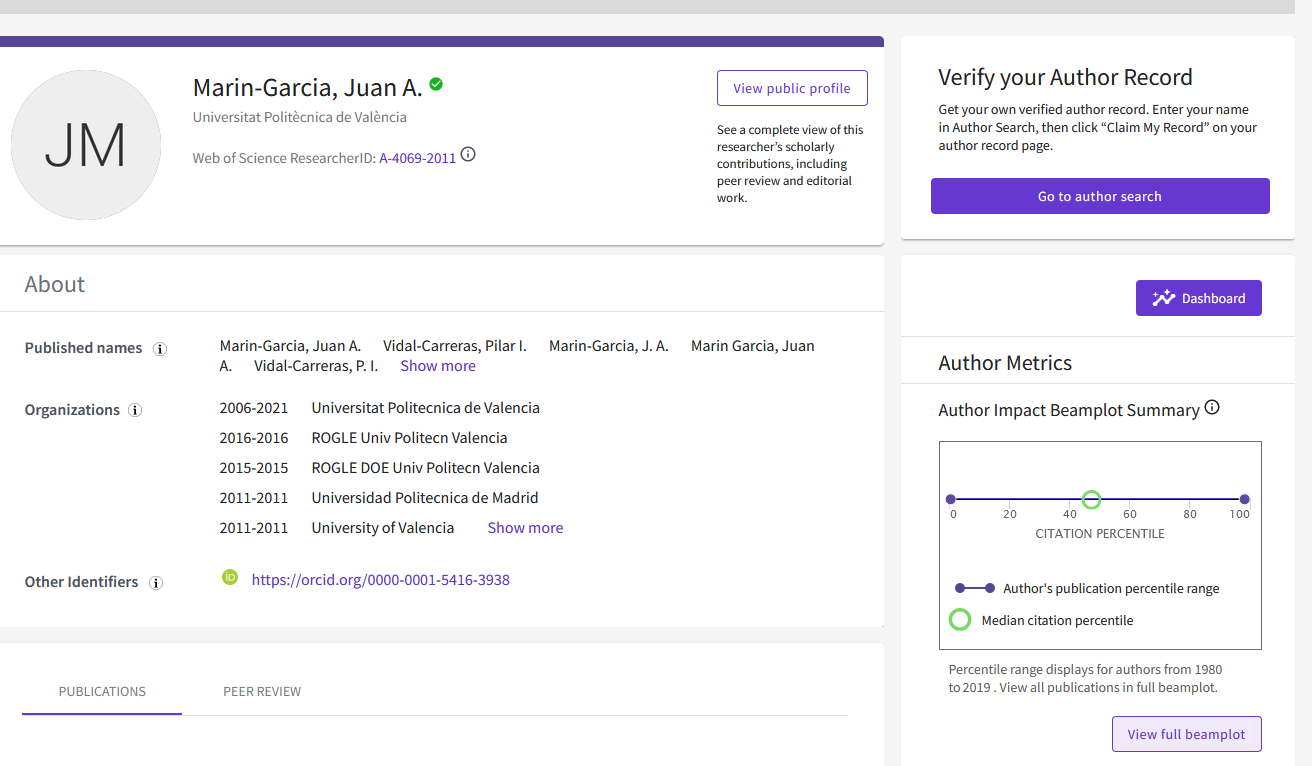
tras pulsar el enlace a un autor-a, te lleva a su página de perfil
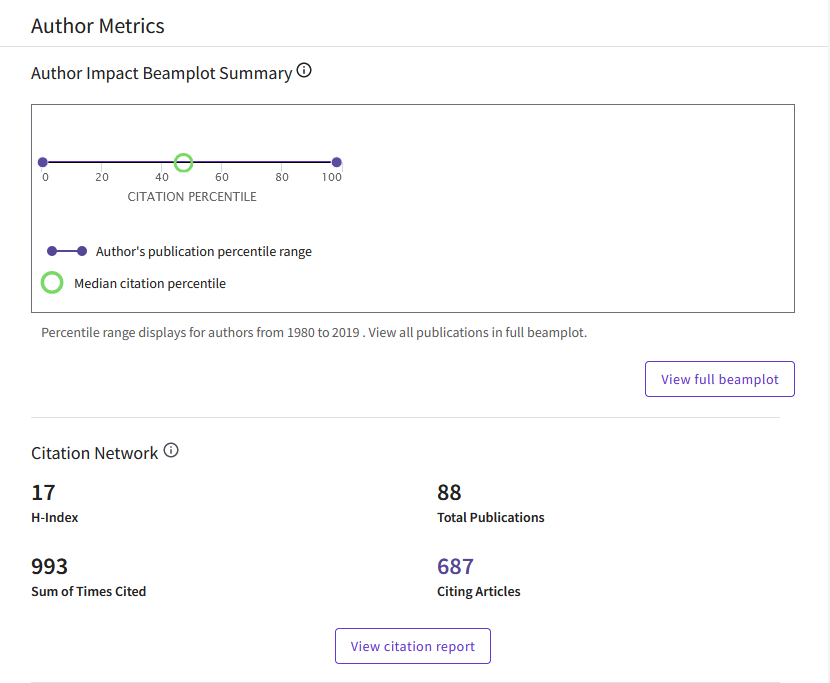
y en la página que se abre con el perfil del autor, te desplazas hacia abajo hasta que encuentres el “Author Impact Beamplot Summary) (insisto, ahora está en la parte de abajo de la página, tras todas las citas de lo publicado. Pero pueden colocarlo en cualquier otro sitio en el futuro). Para ver los detalles, pulsa el botón “View full beamplot”
(solo se incluyen artículos del tipo “article” o “review” data papers u otras contribuciones científicas son ignoradas, de momento, en el “beamplot”.
Una forma más rápida puede ser velo desde la cuenta de Publons (si te has creado una cuenta de estas. Es un producto derivado de WOS que promocionaron mucho hace dos años)
Resolvamos un caso práctico
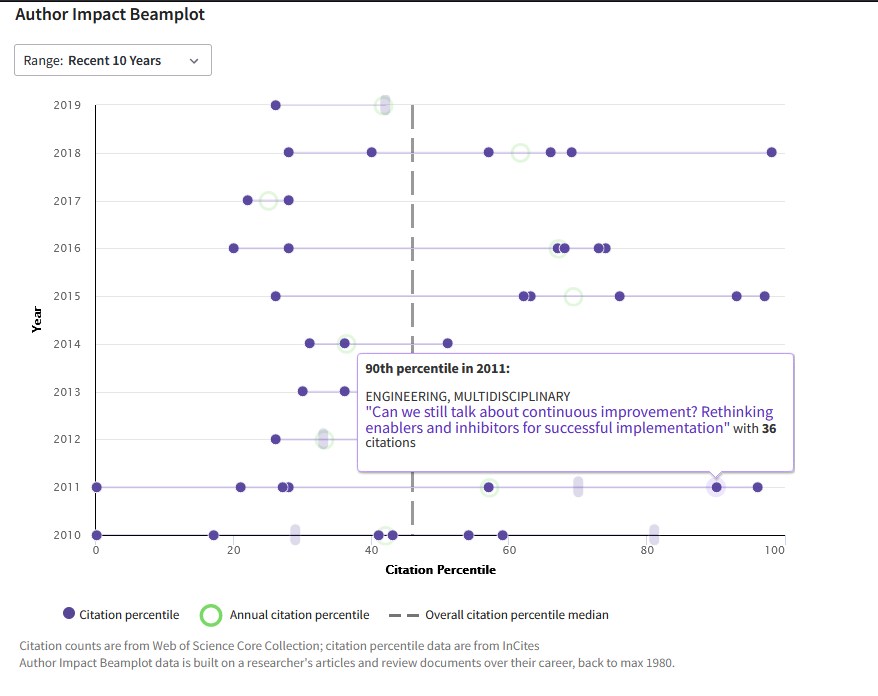
¿Qué posición respecto a impacto en citas tendría este artículo? Garcia-Sabater, J. J., & Marin-Garcia, J. A. (2011). Can we still talk about continuous improvement? Rethinking enablers and inhibitors for successful implementation. International Journal of Technology Management, 55(1/2), 28-42.
(datos recogidos el 29 de septimbre de 2021)
Opción 1: 36 citas Scopus; 36 citas en WOS
El artículo es de 2011, y la temática es de dirección de operaciones, de modo que voy a la tabla de citas de Scopus en la categoría de miscelánea dentro de Business y management, el promedio de citas para artículos de ese año son 13,8. Como el articulo tiene 36 es citado más del doble que el promedio. Si voy a la de WOS en Business es 18.16 y en management es 20,6, de nuevo 30 citas en WOS es casi el doble que el promedio de artículos de ese año en la categoría.
Opción 2:
WOS Beamplot: Busco el perfil de uno de los autores (en este caso el segundo autor), Me desplazo hasta la parte de la página donde esté el gráfico “beamplot” y pulsa el botón “view full beamplot”
y si paso el ratón por encima de uno de los artículos puedo ver los detalles. En este caso voy pasando por todos los de 2011 hasta encontrar el que me interesa. 36 citas en WOS para éste lo sitúa en el percentil 90
Scopus FWCI: busco el artículo en Scopus. En la pagina de detalle abro el campo de “metrics” y las 36 citas para un articulo de 2011 indica un percentil 45% y el FWCI es de 0.26 (que está alejado de 1).
Puede llamar la atención la diferencia de resultados (sobre todo cuando se compara con la tabla de citas de Scopus, que es la misma fuente de datos). Pero no olvidemos que:
The FWCI is the ratio of the document’s citations to the average number of citations received by all similar documents over a three-year window
Seguramente el FWCI no es un buen indicador para articulos antiguos (que seguramente ya no se citan en los últimos tres años, que parece que es la ventana que consideran).
Garcia-Sabater, J. J., & Marin-Garcia, J. A. (2011). Can we still talk about continuous improvement? Rethinking enablers and inhibitors for successful implementation. International Journal of Technology Management, 55(1/2), 28-42.