Que el mundo profesional ha cambiado en los últimos años está fuera de toda duda. La pandemia de COVID-19 y la irrupción de la IA generativa se han sumado a otros cambios que ya se estaban manifestando.
En este contexto, creo que es necesario replantear qué competencias/skills necesitamos formar en nuestros graduados. Quizás no sean necesarios cambios (lo dudo); quizás haya que añadir cosas nuevas; quizás algunas cosas hayan pasado a ser obsoletas. Pero no es trivial dar respuesta a las preguntas: ¿debemos actualizar la formación que ofrecemos? ¿en qué sentido?
Llevo casi dos años dándole vueltas a esto, pero aún no he logrado concretar un marco de trabajo. Entre otras cosas, estaba esperando encontrar alguna investigación que explicara cómo ha cambiado el trabajo profesional en algunas profesiones debido al teletrabajo y otras formas de flexibilidad, la inteligencia artificial generativa y demás condiciones actuales.
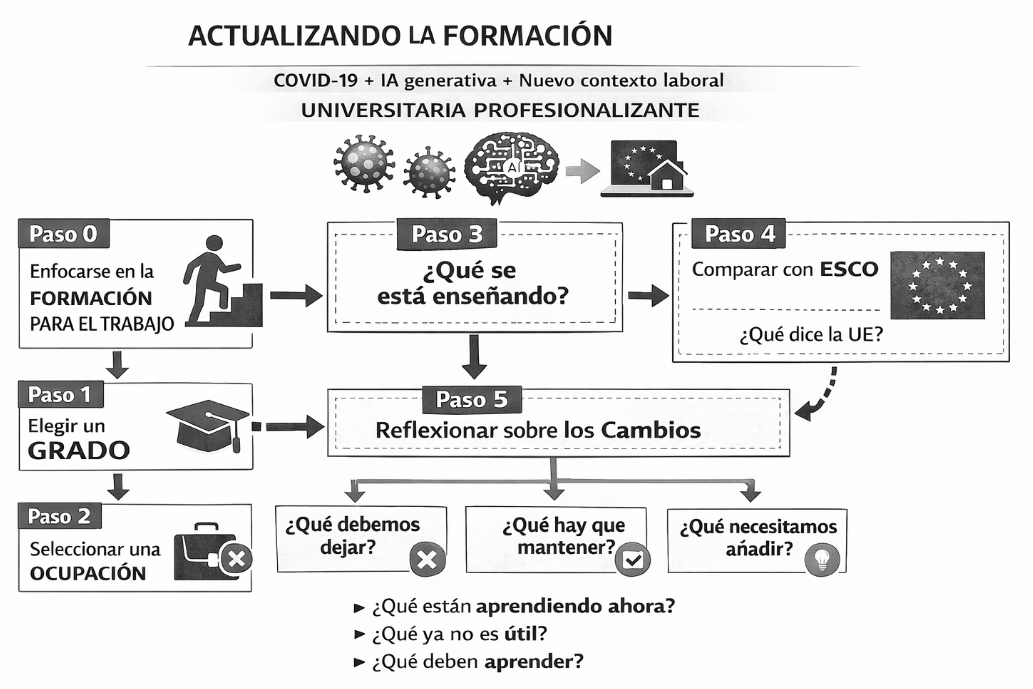
Hoy he decidido crearme un “framework” que no estoy seguro de que me lleve a buen puerto, pero lo comparto, lo intento poner en marcha y luego os comento si me ha funcionado o no.
Paso 0. Decido centrarme en la formación para el trabajo y en ver las necesidades de la persona que usará lo aprendido para ser una profesional. Podría haber elegido otro enfoque, pero creo que este me va a resultar más sencillo y luego por abstracción intentar generalizar hacia otros perfiles.
Paso 1. Elegir un grado para centrarme en él.
Pensar en qué cambios son necesarios a nivel global me resulta demasiado complicado, ya que el impacto del nuevo contexto puede ser muy distinto en cada profesión. Igual luego no lo son tantos, pero me ha parecido más sencillo ir de lo particular a lo general que al revés.
Paso 2. Elegir una ocupación dentro de las que se suponen más comunes afines al grado y centrarme en ella, para luego ir abriendo el abanico a algunas ocupaciones parecidas y ver si hay cambios sustanciales.
Paso 3. Identificar cuáles son las competencias en las que estamos formando actualmente. Es un paso sencillo porque la “verdad” es lo que consta en las memorias de verificación de cada título.
Paso 4. Comparar el resultado del paso 3 con las propuestas oficiales de la Unión Europea.
yo he decidido usar como marco de referencia ESCO. Quizás haya otros marcos mejores, pero este es el que conozco y, en teoría, debería ser un marco sólido.
No obstante, las propuestas de ESCO están ancladas en el pasado. En el mejor de los casos, son buenas propuestas para hace 5 años y tendremos que reflexionar si siguen vigentes o no.
Paso 5. Integrar los resultados de los Pasos 3 y 4 y reflexionar sobre qué cambios son necesarios.
La parte de reflexión la tengo un poco débil. En un mundo ideal, donde las empresas supieran de verdad en qué ha cambiado realmente lo que sus profesionales necesitan, el informante relevante sería la empresa. Pero no estoy muy seguro de que haya alguna que tenga la certeza absoluta de qué es lo que realmente necesitan hoy, ni de qué necesitarán dentro de 5 años. Porque la IA generativa (que es el factor de contexto más influyente actualmente) está en pleno “hype” y poca gente puede tener certeza de dónde, cuándo y cómo va a acabar.
Independientemente de quiénes sean los informantes (ya conseguiré aclararme o usar “muestras de conveniencia” o pedir opinión a mis compañeros académicos para que hagamos el diseño desde nuestras “torres de marfil”), las preguntas clave son:
- ¿Qué están aprendiendo ahora?
- ¿Qué deberían dejar de aprender porque no es útil?
- ¿Qué cosas nuevas deberían empezar a aprender porque las necesitarán para ser buenas profesionales?
Caso de uso:
(en construcción)
GIOI
cuatro perfiles:
Referencias:
European Commission. Directorate General for Employment, Social Affairs and Inclusion. (2019). ESCO handbook: European skills, competences, qualifications and occupations. Publications Office. atlasTI-ART-639 soft Skills. https://data.europa.eu/doi/10.2767/934956
Visitas: 7









{kind=link}